



みなさん、こんにちは。現在OneTechAsiaで働いているNguyen Minh Hieuです。共有をモットーに学習しています。 今日は、Unityで機械学習(マシーンラーニング)を適用するためのちょっとしたデモを作成する方法を皆さんと共有したいと思います。
マシンラーニングの概要
ゲームをプレイしたことがある人は、さまざまな状況を予測し適切な決定を下すことができるボットに出会ったことがあるでしょう。このボットは機械学習(マシーンラーニング)を使用したAIです。
Unity(ユニティ)では、ML-AgentsToolkitを通じてマシンラーニングを設定できます。
この記事では、環境をインストールしてゲームに適用するトレーニングモデルを設定する方法を説明します。
インストール手順
ステップ1:Unity Engineをインストールする (2020.3以降)
ステップ2:Pythonをインストールする(3.6.1以降)
ステップ3:以下のプロジェクトのクローンを作成します: https://github.com/Unity-Technologies/ml-agents
ステップ4:ML-Agentsのプロジェクトフォルダーにアクセスします。次に、python仮想環境を作成するためにディレクトリをCommand Promptします。python -m-venvvenvと入力します

次に、コマンドvenv \ Scripts\activateを使用して仮想環境をアクティブ化します。

Enterキーを押すと、これは成功したときに返される結果です

ステップ5:pytorchをインストール。
pip3 install torch~=1.7.1 -f https://download.pytorch.org/whl/torch_stable.html
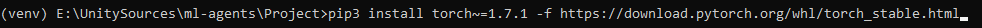
ステップ6:ml-agentsをインストール。
python -m pip install mlagents==0.28.0

基本的に環境の設定は完了です。インストールプロセス中に問題が発生した場合は、次のリンクから詳細を参照できます。
https://github.com/Unity-Technologies/ml-agents/blob/release_19_docs/docs/Installation.md
デモプロジェクトについての簡単な説明
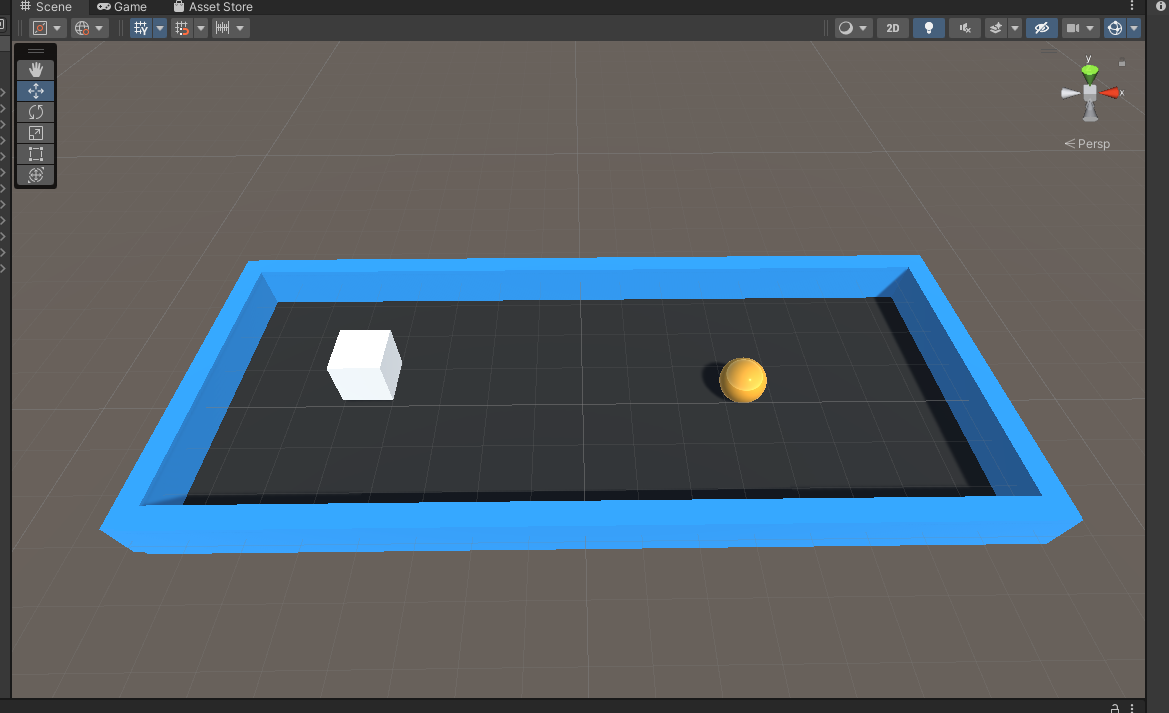
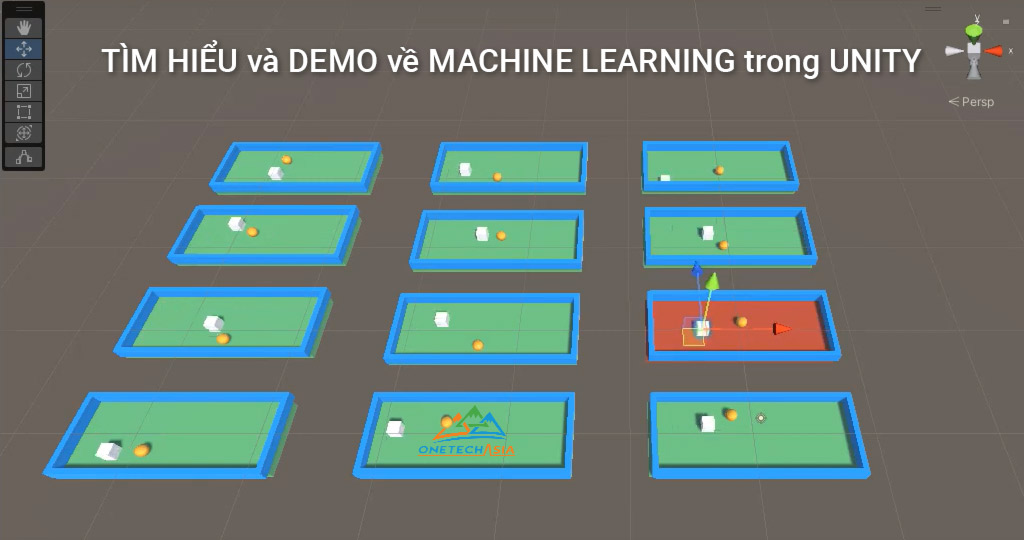
目的:メインオブジェクト(agent)に自分で移動する方法を学習させてから、ターゲットオブジェクト(goal)への独自の方法を見つさせます。
説明:シーンに含まれるもの
- object wallの壁に囲まれたエリア。
- object agent がある。(画像の白い立方体です。)
- object goalがある。(画像の黄色い球です。)
トレーニングプロセスの原則:Agentはランダムに移動するように設定されていて真と偽を学習する。ここでは、壁にぶつかることが偽りであり、ゴールに行くことが真であるを設定します。トレーニングプロセスの結果、onnxファイルを取得します(このファイルは、トレーニング後のAIとして理解できます)。このファイルをAgentに使用すると、壁や最適なパスに触れることなく、正確に移動できます。
シーンデモを作成する
ます、平面(立方体)を作成し、、BoxColliderを追加しましょう。
次に、エージェント(立方体)を作成して、BoxColliderとRigidbodyを追加します。
次に、ゴール(球)と4つの壁を作成し、Box Collider、Rigidbody、script goalまたはscript wallをそれぞれ追加します。そして、下の画像のようにインストールします。
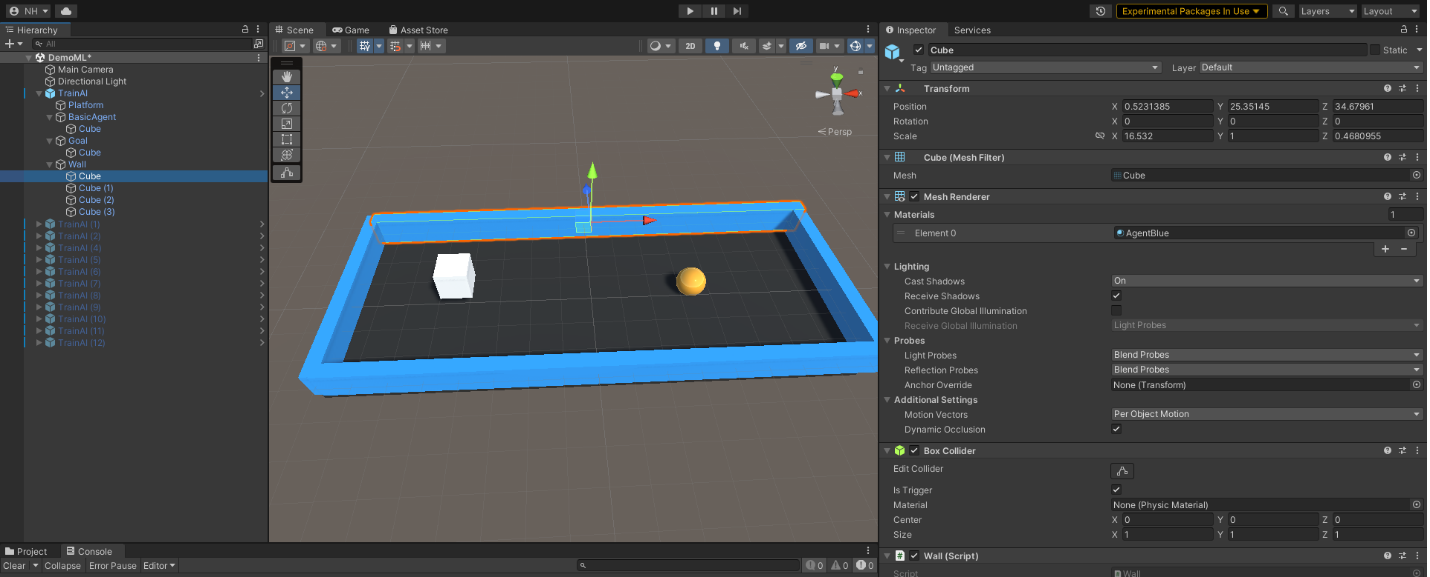

上記のすべてのオブジェクトをTrainAIオブジェクトに属します。
ステップ1:以下は、Agentの入力、出力、移行設定スクリプトです。
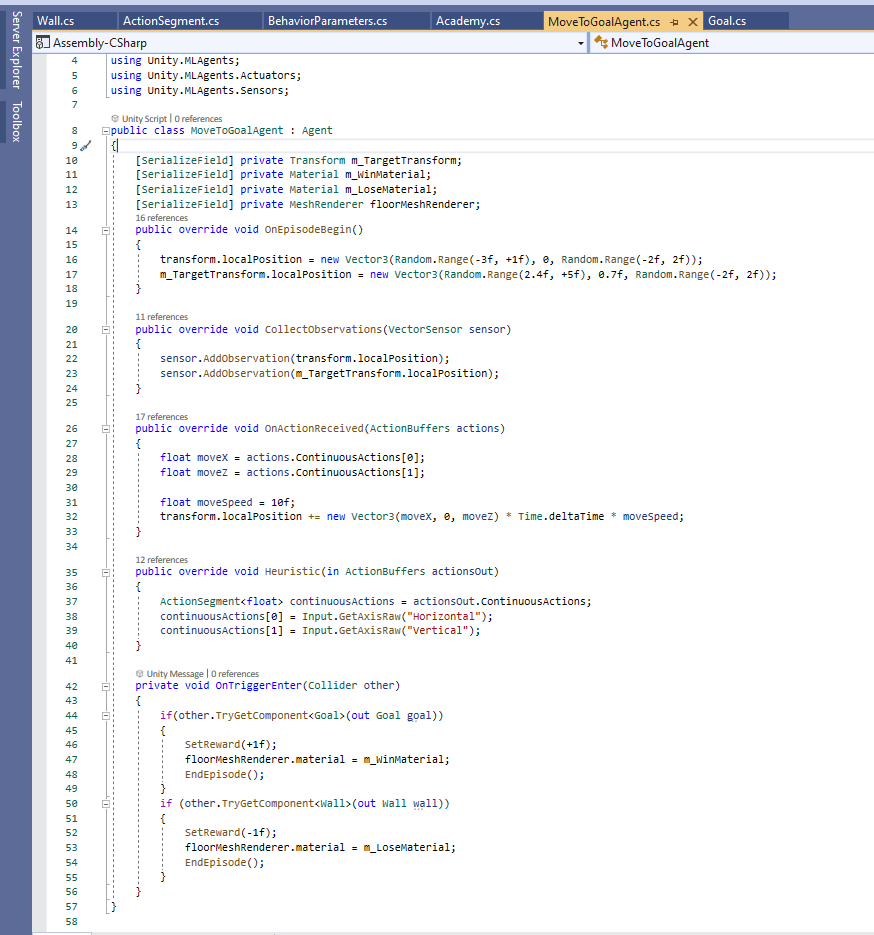
ステップ2:Object Agentに追加し、次のフォームに従って設定します。
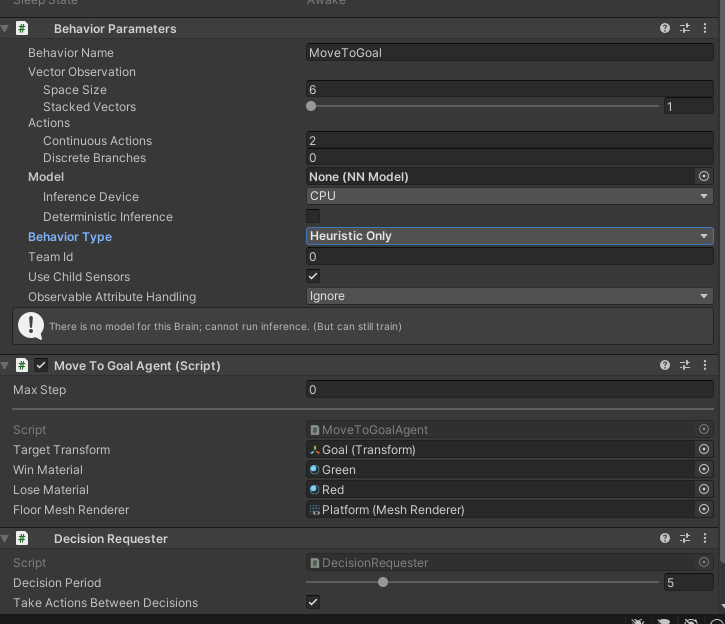
ステップ3:手動テストする。
図5に示すようにBehavior TypeをHeuristic Onlyに設定し、Playを押します。次に、キーボードを使用してエージェントを移動し、壁に触れているかどうかをテストします。床が緑色に変わるかどうかを確認します。次に、目標が達成されたかどうかを確認します。床が赤に変わるかどうかを確認します。最後に、壁にぶつかってゴールに当たった後、エージェントとゴールがランダムであるかどうかを確認します。
ステップ4:モデルをトレーニングする。
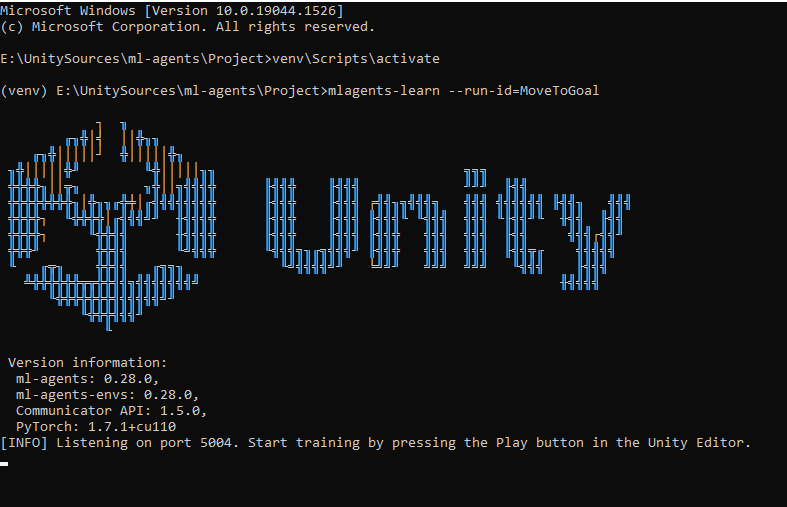
cmdで、次のコードを入力して、train model境を初期化します。 id=name。

これは、トレーニングモデル環境が正常に初期化されたときの結果です。
Unityの横にある[BehaviorType]セクションで、[Default]を選択します
![Unityの横にある[BehaviorType]](https://onetech.jp/wp-content/uploads/2022/03/Tien-hanh-train-cho-Agent-Behavior-type.png)
Object TrainAIが多いほど、Trainプロセスが速くなるという特徴があります。したがって、マシーンの構成に基づいて最適化の検討してください。
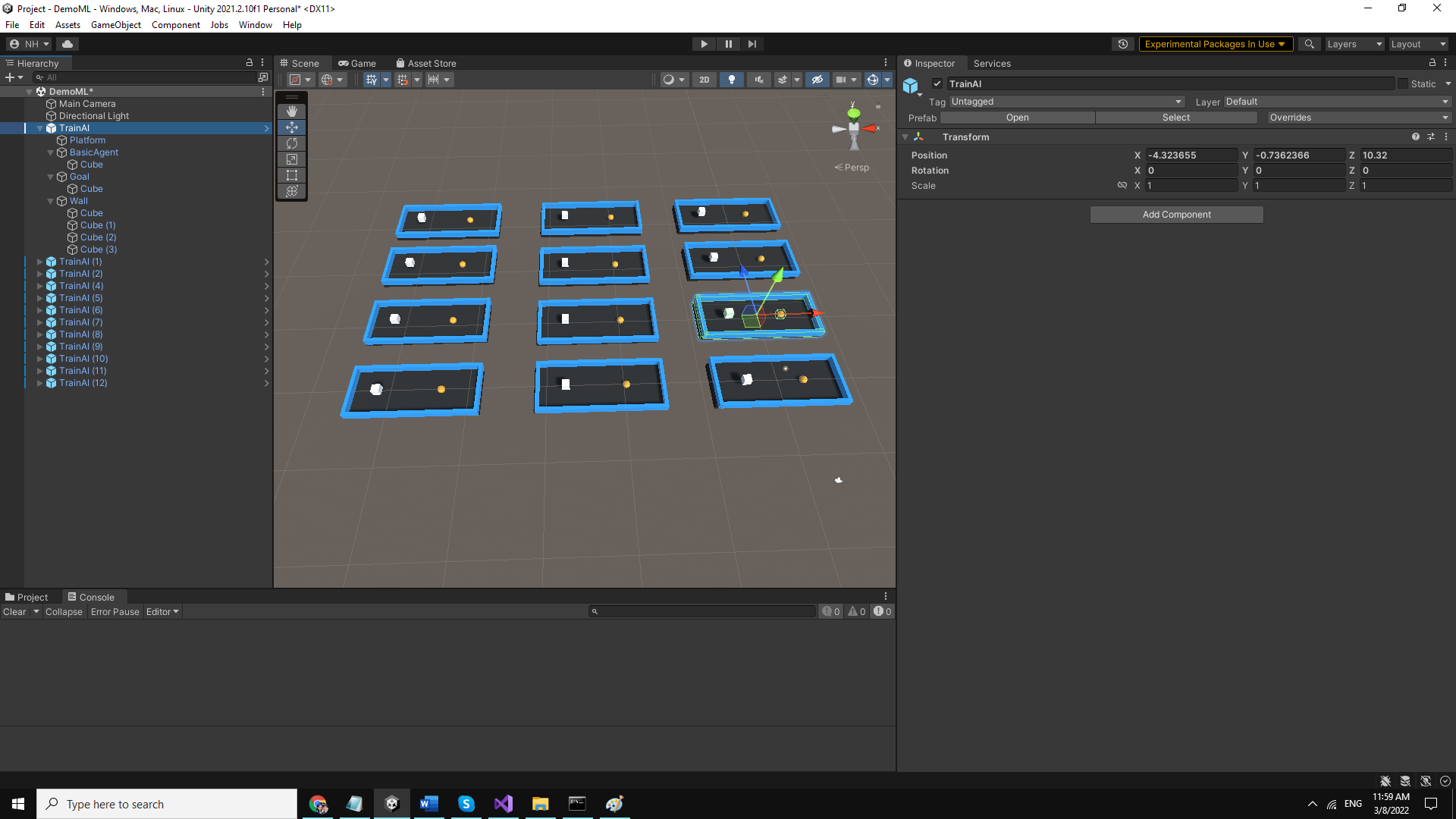
次に、再生を押してトレーニングプロセスを開始します。 トレーニングプロセスを観察し、エージェントがほとんどの場合正しく機能していることを確認したら停止します。
トレーニング結果観察
目視で確認し次の方法でトレーニング時にパラメータを確認することにより精度をより上げることができます。
トレーニング中、新しいcmdを作成します。tensorpoarch–logdir resultsを入力します。

ここではlocalhost:6006を返します。ブラウザを開いてください。
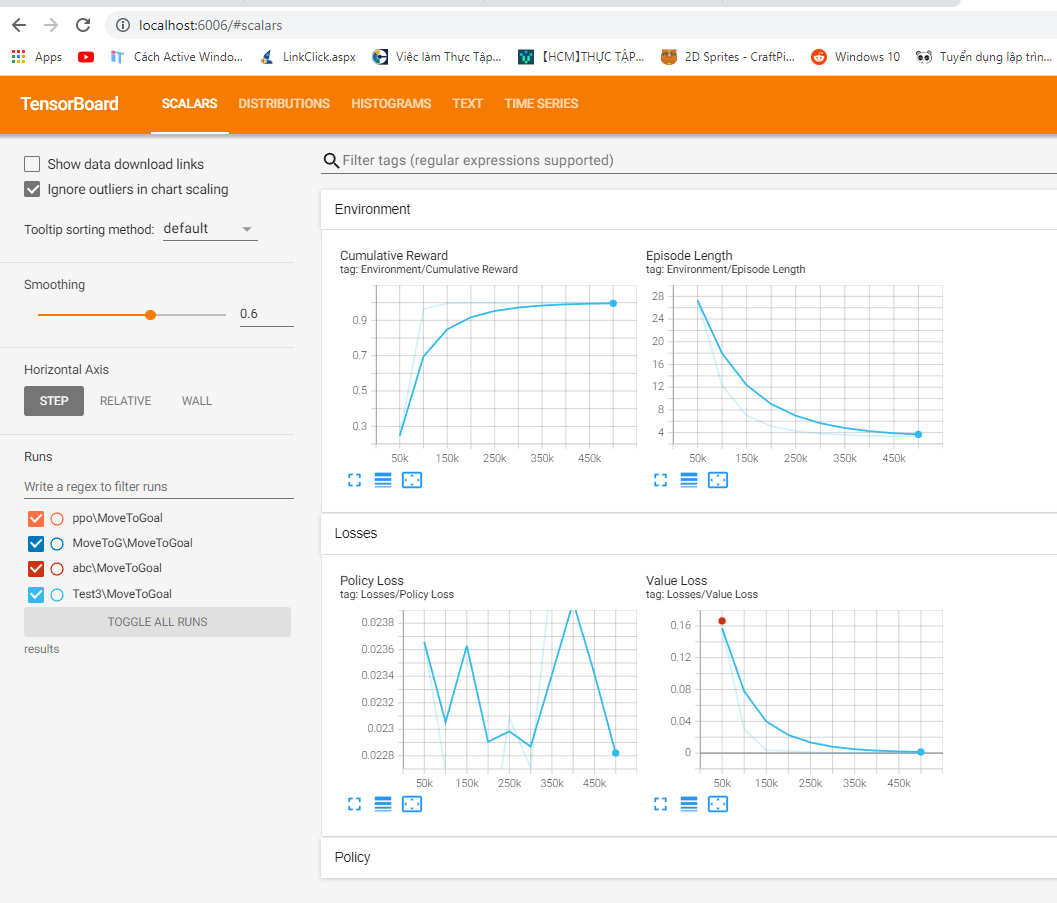
- Cumulative Rewardテーブル観察:パラメーターが0.3から0.9に徐々に増加し、増加し続けていることが認識できます。これは、Agentが壁にぶつかった結果と成功の結果を比較して徐々に高い割合でターゲットを見つけることを意味します。
- Episode Lengthの表:パラメーターが28から4まで徐々に減少し、減少し続けていることがわかります。これは、AIが徐々に速い速度でターゲットを見つけことを意味します。
上記のパラメーターを使用すると、AIがトレーニングされた回数に応じてよりスマートになっていることを確認できます。
Cumulative Reward >0.9 のパラメーターが表示されたら、トレーニングプロセスを終了できます。
トレーニング後のモデル使用
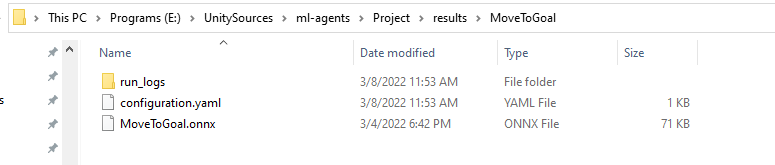
Results/MoveToGoalフォルダーに移動します。ファイルMoveToGoal.onnxをアセットにコピーします。このファイルはAIであり、後で使用するためのAgent の頭脳です。
次に、クローンした11個のTrainAIオブジェクトをすべて非表示にし、元のTrainAIオブジェクトのみを残して、agentでファイルMoveToGoal.onnxをモデルに追加し、Behavior Type をInference Onlyに修理して、MoveToGoal.onnxモデルを使用します。

トレーニングを受けたAgentを取得します。Playをクリックします。
モデルのトレーニングに成功しました。
これはAIを通じて達成された結果であることに注目してください。違いは、Agentが道を見つけるためにロジックをコーディングする必要がないということですが、Agentはそれ自体で目的地に移動することを考えます。
まとめ
実際、Machine learning(マシーンラーニング)は多くの事業分野や生活にも応用され始めています。顔認識システム、ルビックキューブを回転させるロボット、チェスや囲碁などの知的ゲームのAIは非常に有名です。
上記のチュートリアルで、UnityでのMachine learning の基本を理解できます。その後、他のプロジェクトでさらに深く掘り下げて応用することもできるでしょう。皆様の成功を祈っています。







