



「Stable Diffusion」は、生成AIの分野で注目されている技術の一つです。生成AIとは、データから新しいデータを自動で生成する人工知能のことを指します。
今回解説している「Stable Diffusion」は画像生成において高い性能を発揮し、多くのクリエイティブなプロジェクトで利用されています。

本記事では、「Stable Diffusion」の基本概念、仕組み、利用方法、利点と課題について詳しく解説します。
画像生成AI「Stable Diffsion」が気になる方は、ぜひこの記事を読んで参考にしてください。
画像生成AI「Stable Diffusion」とは?
生成AIは、イギリスのスタートアップ企業Stability AIが開発したデータから新しいデータを生成する画像生成AIです。「Stable Diffusion」は画像生成だけでなく、音声生成、テキスト生成など多岐にわたる応用が可能です。
「Stable Diffusion」は、Diffusionモデルをベースにした生成AIであり、他の生成AIと比較して安定性と性能が高いことが特徴です。
数ある生成AIが登場する中、画像生成AI「Stable Diffusion」の大きな特徴としてオープンソースとして提供しているため、ユーザーが無料で「Stable Diffusion」を利用できる点です。
▼公式サイト 画像生成AI Stable Diffusion
https://ja.stability.ai/stable-diffusion
StableDiffusionではどんなモデル生成ができるのか?

画像生成AI「Stable Diffusion」には、次のような機能を持っています。
・テキストから画像への生成(Text To Image)
・画像から画像への生成(Image To Image)
・グラフィック、アートワーク、ロゴの作成
・画像編集とレタッチ
・動画制作
それぞれの生成機能の特徴や実際に生成した画像をまとめました。
・テキストから画像への生成(Text To Image)
ユーザーが入力したテキストをもとにAIが自動で画像を生成します。
こちらの桜の画像は「Stable Diffusion 3.5 Medium」を使って、Text To Imageの機能で作成した画像です。
今回入力したテキスト(プロンプト)は、下記の通りに入力しました。
▼プロンプト
「Japanese garden with cherry blossoms in bloom.(桜が咲いている日本庭園)」
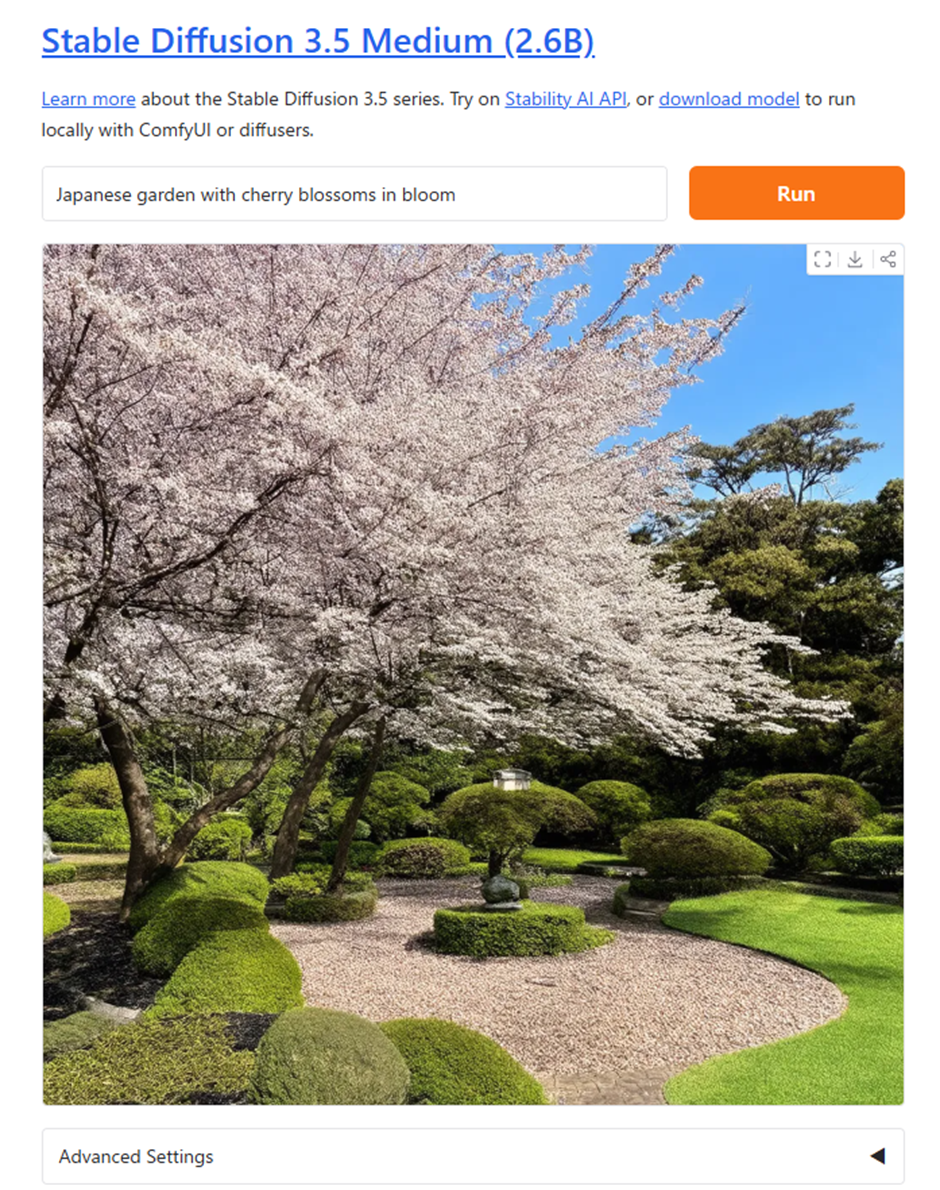
(引用画像:Stable Diffusion)
・画像から画像への生成(Image To Image)
ユーザーが用意した画像をAIに読み込ませ、テキストで指示を加えることで、元画像をベースにテキストの指示に従った新たな画像が生成されます。
・グラフィック、アートワーク、ロゴの作成
選択したプロンプトを使用して、さまざまなスタイルのアートワーク、グラフィック、ロゴを作成できます。もちろん、出力を事前に決定することはできませんが、スケッチを使用してロゴの作成をガイドすることはできます。
▼プロンプト
「Simple icon, ShibaInu illustration.(柴犬のイラスト、シンプルなアイコン)」
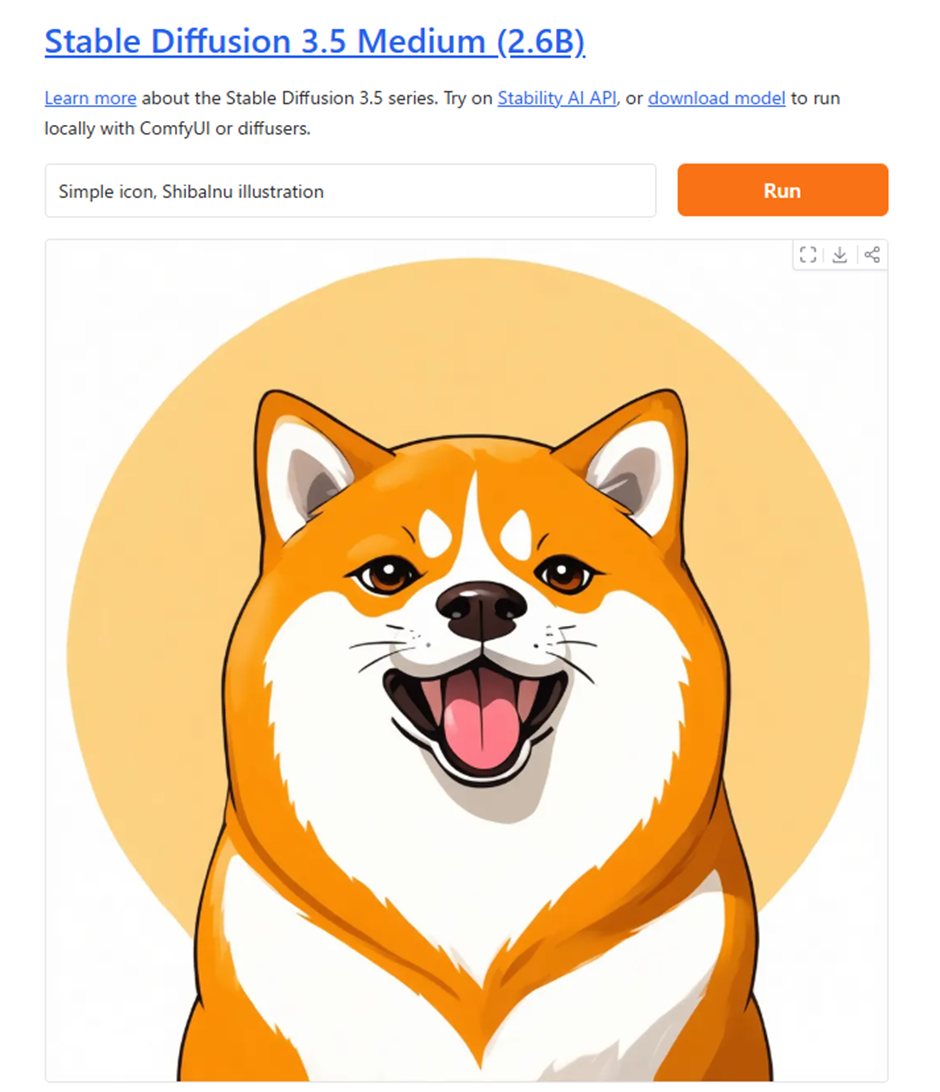
(引用画像:Stable Diffusion)
・画像編集とレタッチ
画像生成AI「Stable Diffusion」を使用して、写真の編集やレタッチを行うことができます。AI Editor を使用して画像を読み込み、消しゴムブラシを使用して編集する領域をマスクします。
次に、目的を定義するプロンプトを生成して、写真を編集または修復します。たとえば、古い写真を修復したり、写真からオブジェクトを削除したり、被写体の特徴を変更したりすることが可能です。
画像生成AI「Stable Diffusion」の拡張機能「HakuImg」などを使えば、本格的な画像加工を行うことも可能です。
・動画制作
Stable Diffusionには「mov2mov」という拡張機能があります。
元となる動画をフレームごとにAIで解析させ、AIの再解釈した結果を動画として生成し出力します。
Stable Diffusionの利用方法とツール

(引用画像:Stable Diffusion)
画像生成AI「Stable Diffusion」を利用するためには、いくつかのツールと十分なPCスペックとリソースが必要です。
画像生成AI「Stable Diffusion」の使い方
画像生成AI「Stable Diffusion」を使うには、Webブラウザ上で構築された環境で生成AIを動かすか、ローカル環境で独自環境を作って動かすかの二通りがあります。
① Webアプリケーション上の環境で生成する
② ユーザー自身が作成した環境にStable Diffusionをインストールする、
もしくはプログラミングコードを書いて生成する
①はWebブラウザ上で利用できるプラットフォームがあり、アカウントを登録すれば簡単に画像生成AI「Stable Diffusion」を利用できます。
下記のプラットフォームで画像生成AI「Stable Diffusion」を利用することが可能です。
・mage.space
・Hugging Face
・Dream Studio
②は自分のPCにStableDiffusionをインストールしてローカルな環境で使用する方法です。
「Stable Diffusion web UI」というツールを利用すると、詳細な設定をおこなうことができます。
はじめて画像生成AI「Stable Diffusion」を使う場合は、①のWebブラウザ版から始めることをおすすめします。
Stable Diffusionを使うためのツールとリソース
画像生成AI「Stable Diffusion」を利用するためには、適切なハードウェアとソフトウェアが必要です。例えば、高性能なGPUを搭載したコンピュータや、画像生成AI「Stable Diffusion」のライブラリをインストールするためのソフトウェア環境が必要です。
下記の表は、画像生成AI「Stable Diffusion」を使用するうえで推奨PCスペックをまとめました。
| 推奨スペック | |
| 使用するPC | デスクトップ |
| OS | Windows(64bit) |
| CPU | 最新モデルのCore i5~i7、Ryzen5~7 |
| GPU | RTX 30シリーズ、RTX 40シリーズの VRAMが12GB以上 |
| メモリ | 16GB~32GB(学習させる場合は32GB) |
| ストレージ | 512GB以上(可能なら1TB) |
(引用:Dospara plus)
Q.OSはWindowsのほうがいいのか?
Stable Diffusionを利用する場合、macOSよりWindowsOSをおすすめします。
公式からもStable DiffusionではWindowsが推奨OS であると言及しています。
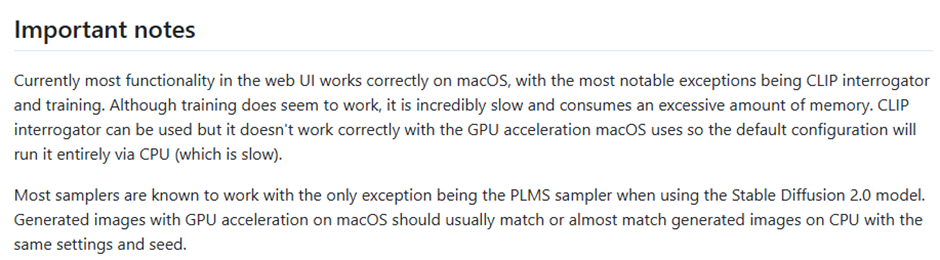
(引用画像:Stable Diffusion webUIドキュメント)
▼日本訳
現在、Web UIのほとんどの機能はmacOSで正しく動作しますが、最も顕著な例外はCLIPインテロゲーターとトレーニングです。トレーニングは機能しているように見えますが、信じられないほど遅く、メモリを過剰に消費します。
CLIPインテロゲーターは使用できますが、macOSが使用するGPUアクセラレーションでは正しく動作しないため、デフォルトの構成では完全にCPU経由で実行されます(これは低速です)
画像生成AI「Stable Diffusion」では、VRAMの容量が4GB以下だとメモリ不足によるエラーが発生します。エラーの発生によりAIイラストを生成できない場合があるため、スペックのいいPCを用意する必要があるでしょう。
Stable Diffusionの利点と課題
画像生成AI「Stable Diffusion」は手軽なスキャンによる使いやすさが大きな利点ですが、スキャンデータの精度の限界などの課題もあります。
この章では画像生成AI「Stable Diffusion」の利点と課題をあげ、それぞれ詳しく解説していきます。利点と課題を理解し、自分にあった画像生成AIの使い方を考えましょう。
Stable Diffusionの利点
画像生成AI「Stable Diffusion」の利点としては、次の3点があげられます。
利点①無料で利用が可能
利点②汎用性が高い
利点③デバイスの制限がない
それぞれ画像生成AI「Stable Diffusion」の利点を解説していきます。
利点①無料で利用が可能
画像生成AI「Stable Diffusion」は、オープンソースで公開されているAIのため、ユーザーは無料で利用することができます。
利点②汎用性が高い
リアル調からアニメ風まで様々な画像生成を行うことができます。
ベース画像、生成する画像の数、出力画像の解像度などを調整するオプション機能もあり、汎用性が高いです。
利点③デバイスの制限がない
画像生成AI「Stable Diffusion」は、出力時間や利用時間に制限がない点が大きな利点になります。
サブスクリプションで課金する場合、使用できるデバイスにも制限がつく場合がありますが、画像生成AI「Stable Diffusion」はデバイスの制限がありません。
出力画像や利用時間の制限もかからないことが特徴です。
Stable Diffusionの課題
一方で画像生成AI「Stable Diffusion」にも課題があります。注意しなければいけない課題として、次の3つがあげられます。
課題①データ容量の制限あり
課題②利用できるハードウェアに条件あり
課題③webブラウザ版はカスタマイズに制限あり
それぞれ画像生成AI「Stable Diffusion」の課題を解説していきます。
課題①データ容量の制限あり
画像生成AI「Stable Diffusion」では、VRAMの容量が4GB以下だとメモリ不足によるエラーが発生します。
エラーの発生により、AIイラストを生成できない場合やAIの学習自体ができない、また高解像度のイラストを生成できないなど様々な問題が発生します。
PCのスペックが低い場合、上記のエラーに注意が必要です。
課題②利用できるハードウェアに条件あり
画像生成AI「Stable Diffusion」のPCスペック条件が高い必要があります。
しかし安定した状態で画像生成AIを行うには、高スペックのPCになるため、個人ユーザーには負担かもしれません。
課題③webブラウザ版はカスタマイズに制限あり
画像生成AI「Stable Diffusion」は、webブラウザ上で利用できるオンライン版があり、こちらはハードウェアのスペックに依存しません。
しかし無料で生成できる画像の枚数に限りがあったり、カスタマイズ性に制限がかかっています。
まとめ

(引用画像:Stable Diffusion)
いかがでしたか?この記事は画像生成AI「StableDiffusion」について記事にまとめました。
画像生成AI「Stable Diffusion」は、カスタマイズ性の高さと無料で利用できる点から生成AIを初めて使う初心者の方におすすめです。
画像生成AIは他にもあるので、自分がどんな目的で生成AIを使いたいのか目的を明確にし、自分にあった画像生成AIを選ぶといいでしょう。
画像生成AIについてお悩みのことがあれば、ONETECHにご相談ください。ONETECHでは、AIのアプリシステムを制作した実績もあり、画像生成AIについても相談に乗れます。
下記のリンクはONETECHのAIでの開発実績になります。
▼商品のAI画像認識のための学習モデル用のCG制作
商品のAI画像認識のための学習モデル用のCG制作 | ONETECH開発実績
▼ディープラーニングを使ったテスト採点システムのAI追加改修
ディープラーニングを使ったテスト採点システムのAI追加改修 | ONETECH開発実績
ほかにもONETECHはベトナムオフショア開発で受託開発も請け負っております。幅広い分野で開発してきた実績がありますので、ソフトウェア開発のご相談はぜひOne Technology Japanへお気軽にお問い合わせください。
施工管理を劇的に改善するinsightscanX
iPhoneで簡単に現場を撮影し、3Dでさまざまな課題を管理できるツールです。
画像生成AI「Stable Diffusion」を駆使し現在の業務を半自動化します。
2025年春にリリース予定。
建設業の工程管理を劇的に変える 「InSightScanX」。







