DynamoDBは、アマゾンウェブサービス(AWS)が提供するNoSQLデータベースです。これは、AWSによって完全に管理される、拡張性と柔軟性に優れた非リレーショナルデータベースサービスです。DynamoDBは、高いパフォーマンス、高速な読み取り/書き込み、自動スケーラビリティを提供するように設計されています。DynamoDBは、アマゾンウェブサービス(AWS)が提供するNoSQLデータベースです。これは、AWSによって完全に管理される、拡張性と柔軟性に優れた非リレーショナルデータベースサービスです。DynamoDBは、高いパフォーマンス、高速な読み取り/書き込み、自動スケーラビリティを提供するように設計されています。DynamoDBは、アマゾンウェブサービス(AWS)が提供するNoSQLデータベースです。これは、AWSによって完全に管理される、拡張性と柔軟性に優れた非リレーショナルデータベースサービスです。DynamoDBは、高いパフォーマンス、高速な読み取り/書き込み、自動スケーラビリティを提供するように設計されています。

次の記事では、DymanoDBの優れた機能と利点を紹介します。
DynamoDBの負荷容量
DynamoDBは復元力が高く、シームレスに拡張できるように設計されています。分散型アーキテクチャを採用しており、データは多くの異なるサーバーやリージョンに分散されます。これにより、DynamoDBは1秒あたり数百万の読み取り/書き込みリクエストを処理できるようになります。
DynamoDBが高い負荷容量を達成するのに役立ついくつかの重要な機能:<
- パーティションとデータ分散: DynamoDB内のデータは次のとおりです。複数のパーティションに分割され、複数のサーバーに分散されるため、並列読み込みと簡単なスケーリングが可能になります。
- 読み取り/書き込みのチューニング: DynamoDBを使用すると、ユーザーはアプリケーションのパフォーマンスのニーズに合わせて1秒あたりの読み取り/書き込みキャパシティユニットを調整できます。
- 階層と乗算の自動スケーリング: DynamoDBには、読み取り/書き込みボリュームの増加に応じてデータを自動的に拡張およびスケーリングする機能があり、手動介入なしで安定したパフォーマンスを確保できます。
- レプリケーションの冗長性: DynamoDBは、同じAWSリージョン内の複数のリージョンにまたがってデータを自動的にバックアップし、データの復元性と高負荷容量を確保します。

DynamoDBにおけるマルチテーブルとシングルテーブルの関係の違い
マルチテーブル
- マルチテーブルモデルでは、データはさまざまなテーブルに分割されます。エンティティ間の関係について説明します。
- 各テーブルはエンティティを表し、そのエンティティに関連する属性が含まれます。
- エンティティ間の関係(1対多、多対など)to-many)は、他のテーブルのレコードを参照するために外部キーを使用して表現されます。
- モデルマルチテーブルは、複雑なデータ構造とエンティティ間の多くの関係を持つアプリケーションに適していますが、読み取りパフォーマンスが非常に遅くなります。
リレーションシップを持つ単一テーブル)<
- リレーションを持つ単一テーブルモデルでは、すべてのデータが1つのテーブルに保存されます。
- リレーションシップエンティティ間のデータは、関連するデータを同じレコードにネストすることで表現されます。
- これは、DynamoDBで配列やネストされたオブジェクトなどの複雑なデータ型を使用することで実現されます。
- 単一テーブルリレーションを含むモデルは、多くの場合、より単純なデータ構造とそれほど複雑ではないリレーションシップを持つアプリケーションに適しています。
- 関連するデータを取得するために必要なデータリクエストの数を減らし、読み取りパフォーマンスを向上させるのに役立ちます。
どちらのモデルにも独自の長所と短所があります。DynamoDBのリレーションを使用して複数テーブルと単一テーブルのどちらを選択するかは、アプリケーションのデータ構造、リレーションシップの複雑さ、読み取りおよび書き込みのパフォーマンス要件によって異なります。
単一テーブル内のDymanoDBデータリレーション
この記事では、パフォーマンスと効率を向上させるための単一テーブル内のリレーションについて学習します。
データ間のリレーションシップを構築する「単一テーブル」モデルの例カテゴリと製品。この関係のデータモデルを設計する方法は次のとおりです。
データモデル
単一のテーブルproductsを使用して、製品とカテゴリの情報を保存します。このテーブルの各レコードには、製品またはカテゴリに関する情報が含まれます。
productsテーブルのレコードのデータ構造は次のようになります:
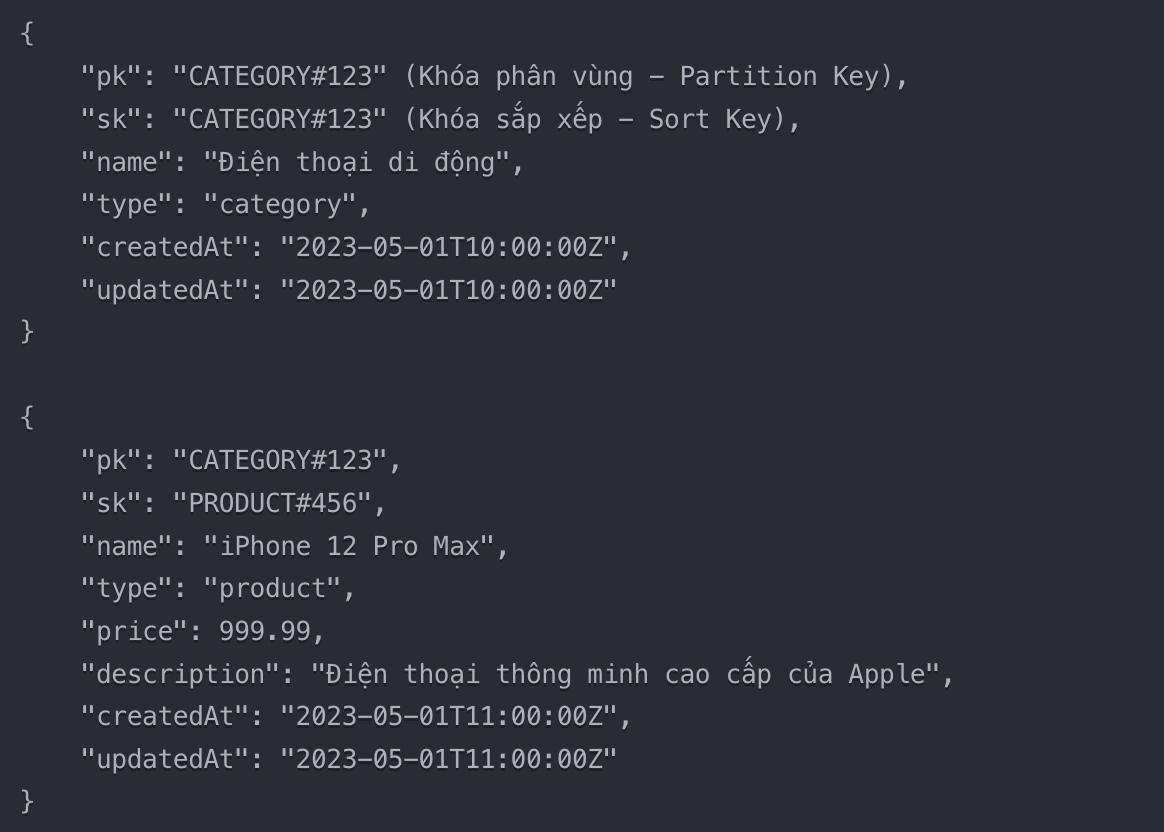
上記のコードでは:<
- pk(パーティションキー)は、タイプ(カテゴリまたは製品)とカテゴリID(同じカテゴリに属するカテゴリと製品の両方)の組み合わせです。
- sk(ソートキー)は、レコード(カテゴリまたは製品)のタイプとIDの組み合わせです。
- これにより、クエリを使用してカテゴリ固有のアイテムに属するすべての製品を取得できます。対応するPK。
新しいカテゴリを追加する
新しいカテゴリを追加するには、「カテゴリ」タイプの新しいレコードとそのカテゴリのその他の情報フィールドを作成します。
カテゴリに新しい製品を追加します
目的新しい製品をカタログに追加するには、タイプ「製品」、その製品を含むカテゴリに対応するpk、および製品のその他の情報フィールドを持つ新しいレコードを作成します。
特定のカテゴリの製品をクエリする
特定のカテゴリ内のすべての製品を取得するには、そのカテゴリに対応するpkと「PRODUCT」で始まるskを含むクエリを使用できます。

結論
この「単一テーブル」モデルを使用すると、別のテーブルを使用せずに、DynamoDBでカテゴリーと製品の間の関係を簡単に構築できます。ただし、このモデルには、データの整合性を維持するのが難しいことや、製品やカテゴリの数が多い場合のスケーラビリティの制限など、いくつかの制限もあります。したがって、アプリケーションの要件に応じて、最高のパフォーマンスと