AWS GLUE の紹介
AWS GLUE は、データの抽出 (Extract)、変換 (Transform)、およびロード (Load) を自動化するために開発されたサーバーレス ツールです。このプロセスは ETL と呼ばれます。AWS GLUE は、企業がデータソースからデータを抽出し、データを変換し、それをデータウェアハウスにロードすることを可能にします。すべてがクラウド上で実行されます。AWS GLUE は、Amazon が完全に管理するサービスでもあります。つまり、ユーザーは管理や保守を行う必要がありません。
なぜ AWS GLUE は強力なのか?
AWS GLUE は強力である理由は、Apache Spark のスピードとパフォーマンスと、Hive のデータ整理を組み合わせているためです。Lambda という、AWS のもう 1 つの完全に管理されたサービスについて聞いたことがあるかもしれません。Lambda の待機時間が 15 分であるのに対し、AWS GLUE の待機時間はデフォルトで 2 日です。Lambda を使用していくつかのプロジェクトで実行時間が長すぎる場合、問題に応じて AWS GLUE を選択できます。
AWS GLUE は、データ分析の時間を短縮することで、データの統合をより迅速に行うことができます。また、データの準備タスクを自動化することで、データソースをスキャンし、データ形式を識別し、データの保存に適したスキーマを提供します。AWS GLUE はサーバーレスで実行されるため、管理、プロビジョニング、構成、またはリソースのスケーリングを行う必要はありません。実行中に使用されるリソースに対してのみ料金が発生します。
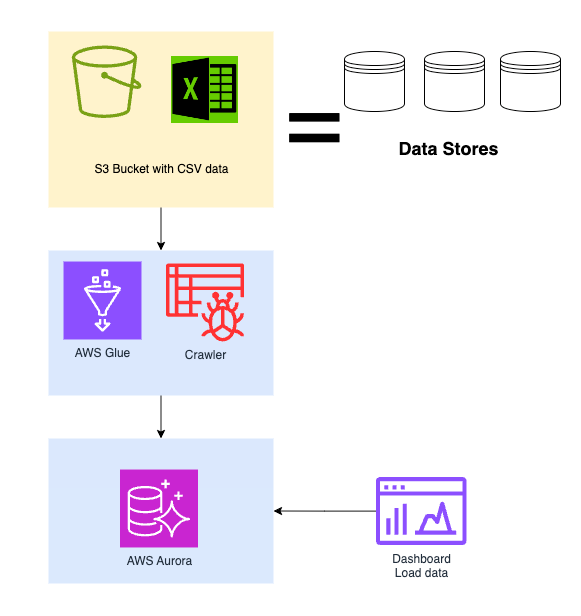
ストリームプロセッサの説明:
- S3 は、テーブル データが CSV ファイル (Oracle データ) の形式で保存される場所です。
- AWS Glue は CSV ファイルをクロールしてテーブルデータを一時的に作成します
- 一時テーブルのデータから更新更新を Aurora Mysql に変換します
準備:
AWS Glueを使用する前に実行する必要があるいくつかの手順
1. AWSアカウントの設定
- このガイドを実行するためには、AWSアカウントが必要です。アカウントを作成するには、こちらをクリックしてください。
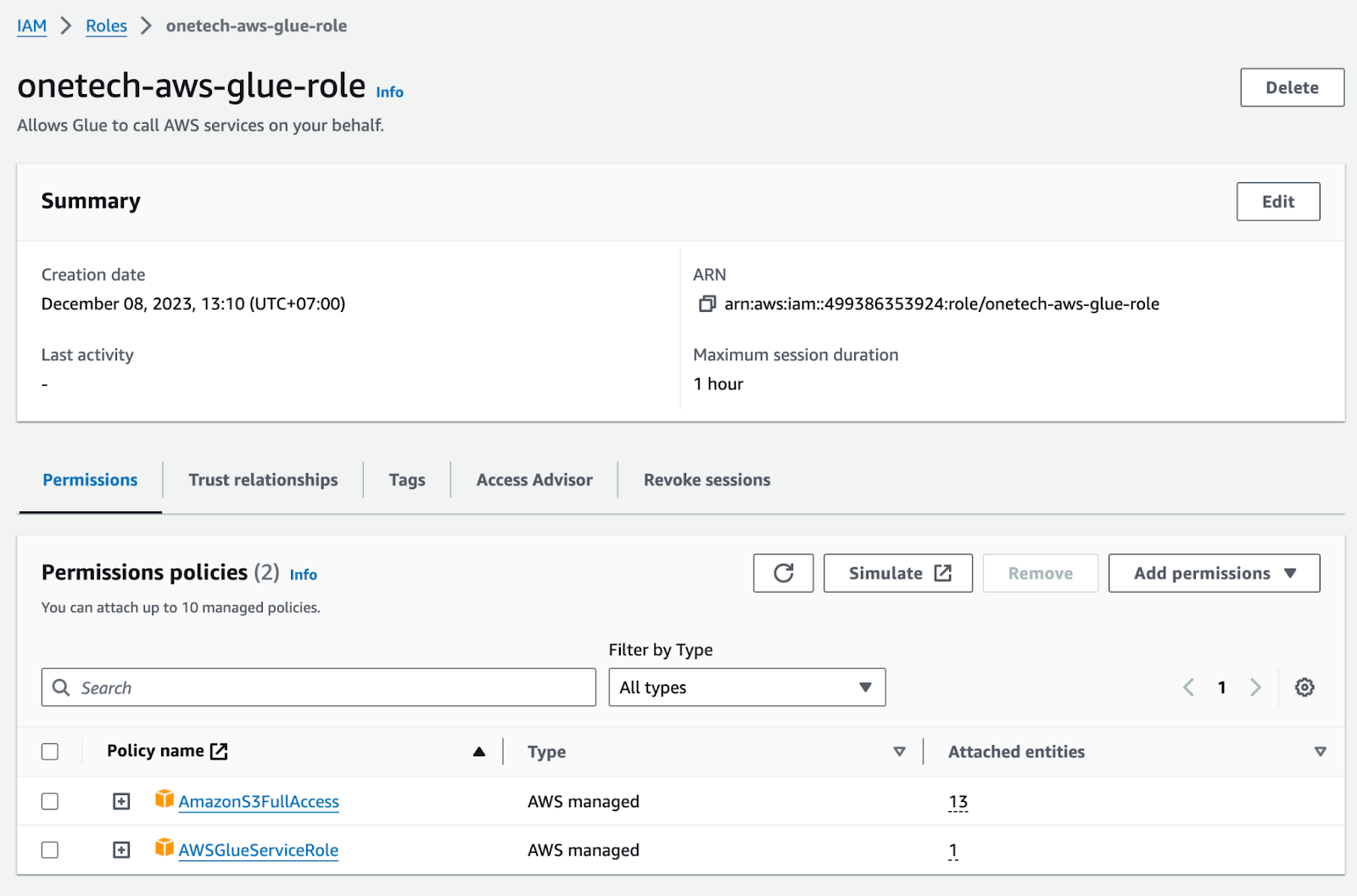
2. AWS Glue用のIAMロールの作成
- AWSコンソールにサインイン > IAM > ロールを選択してロールを作成します。ここで、このロールを使用するサービスとしてGlueを選択します。次に、AWSGlueServiceRoleとS3FullAccessポリシーを選択し、ロールを作成します。
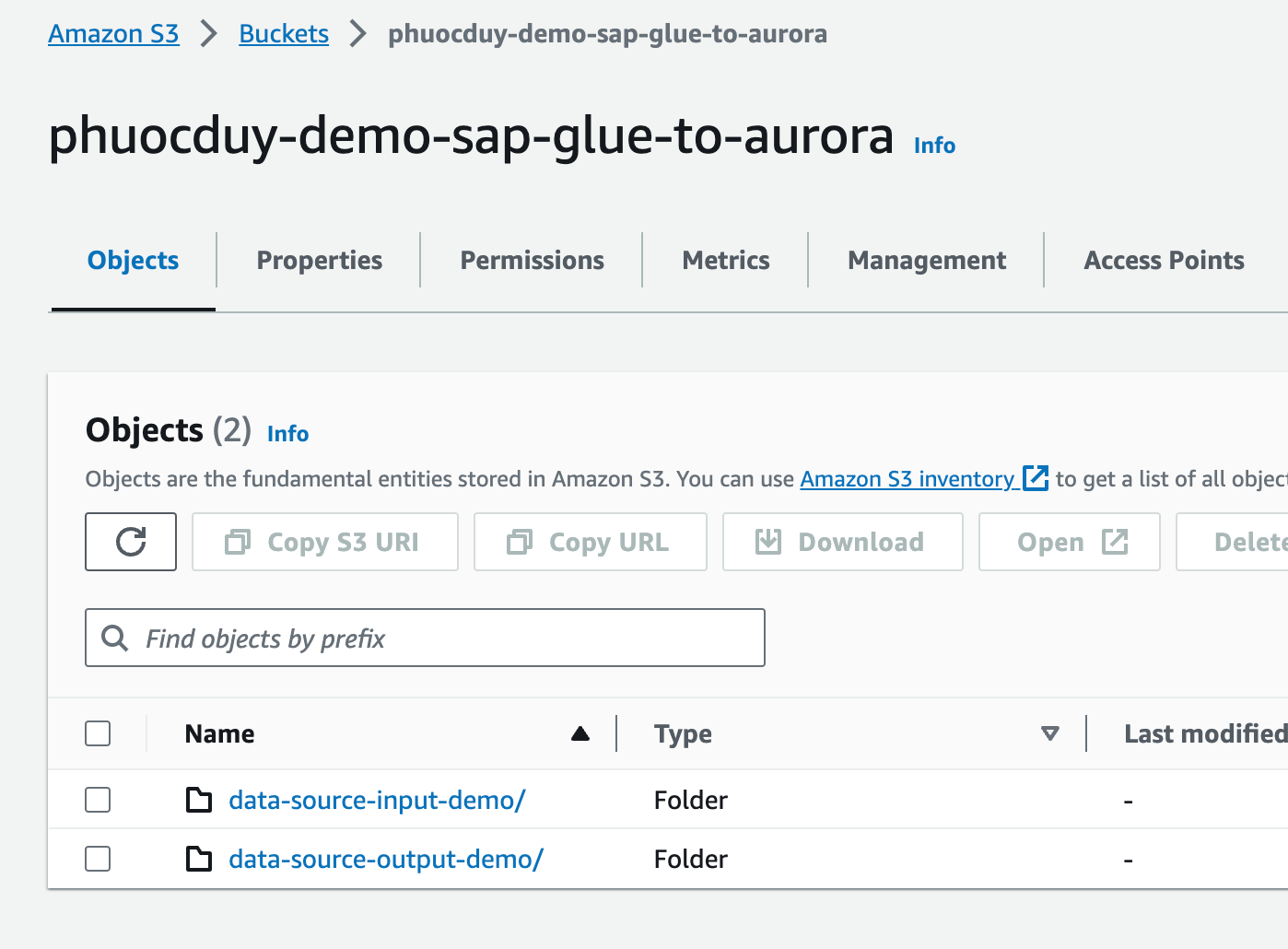
3. “S3バケット với 2フォルダ
data-source-input-demo/ > CSVの入力を含むフォルダ
data-source-output-demo/ > GlueからのCSVの出力を含むフォルダ”
data-source-input-demo/ の中に
Auroraへの入力プロセスを処理するためのテーブルを準備します
資料グループ
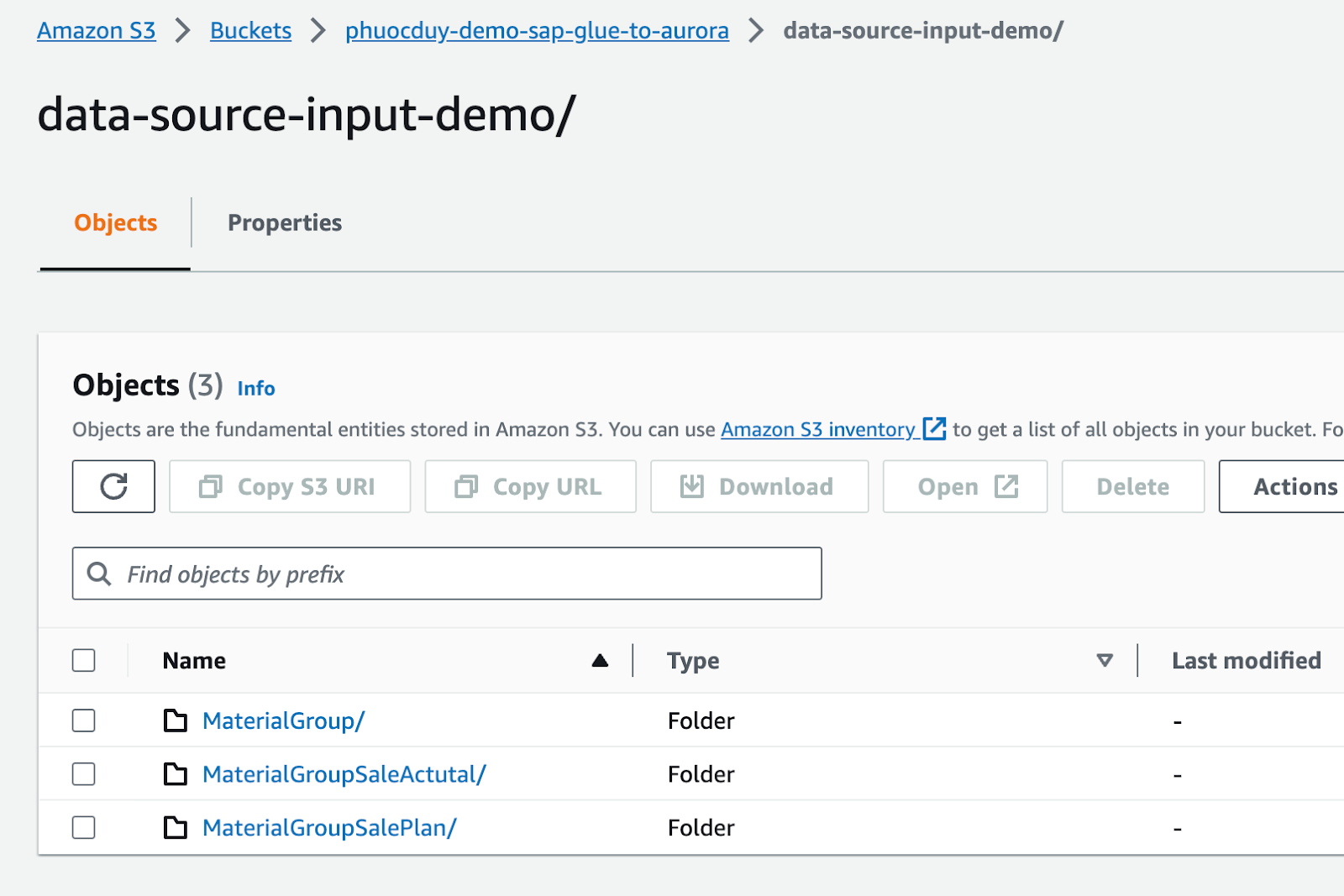
4. Glueデータカタログの作成方法
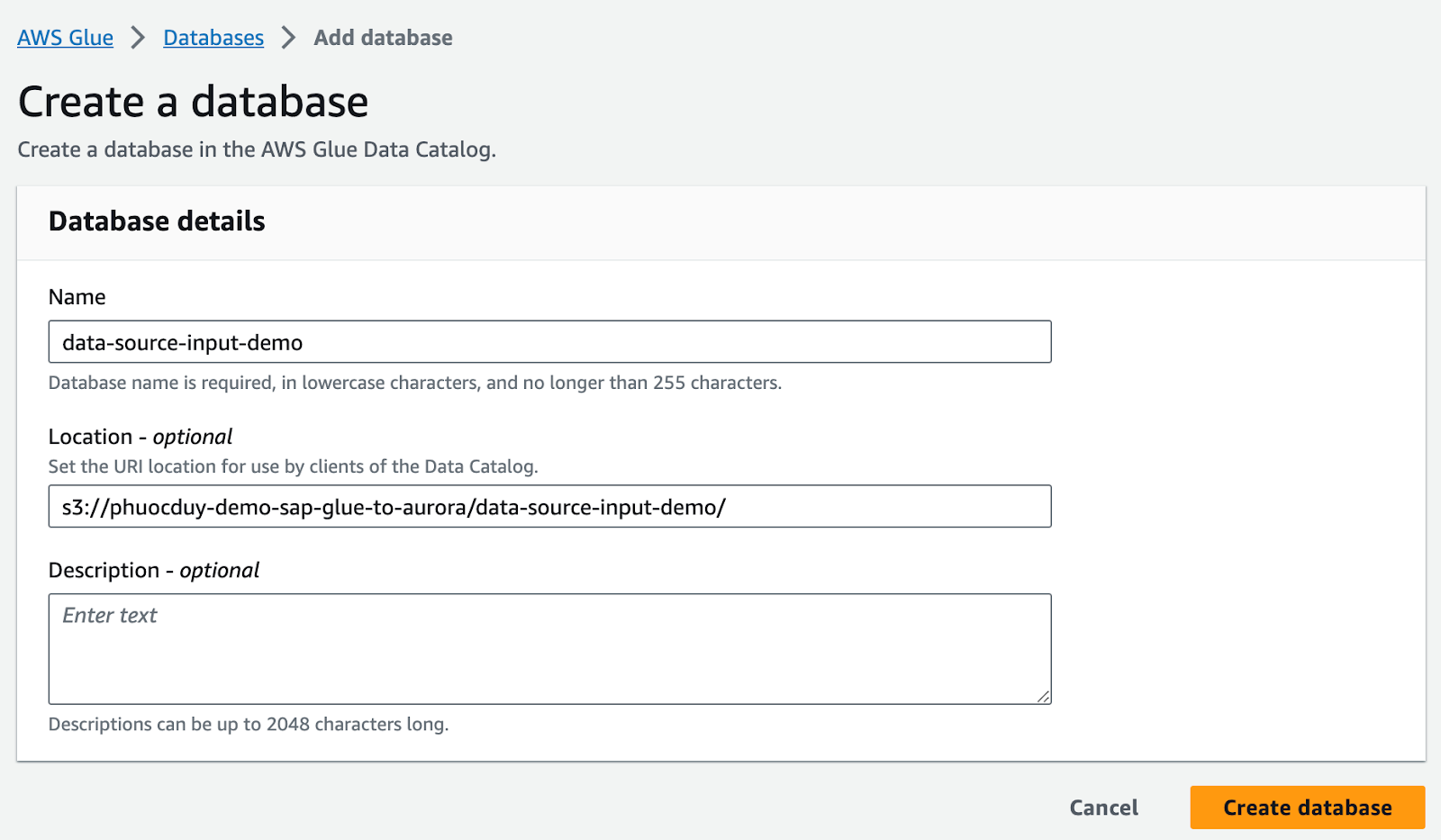
AWS Glueコンソール画面に移動 -> データベース -> データベースの追加
Data-source-input-demo
5. S3上のCSVファイルを使用してテーブルを作成する
AWSコンソールのGlue > テーブル > クローラーを使用してテーブルを追加:
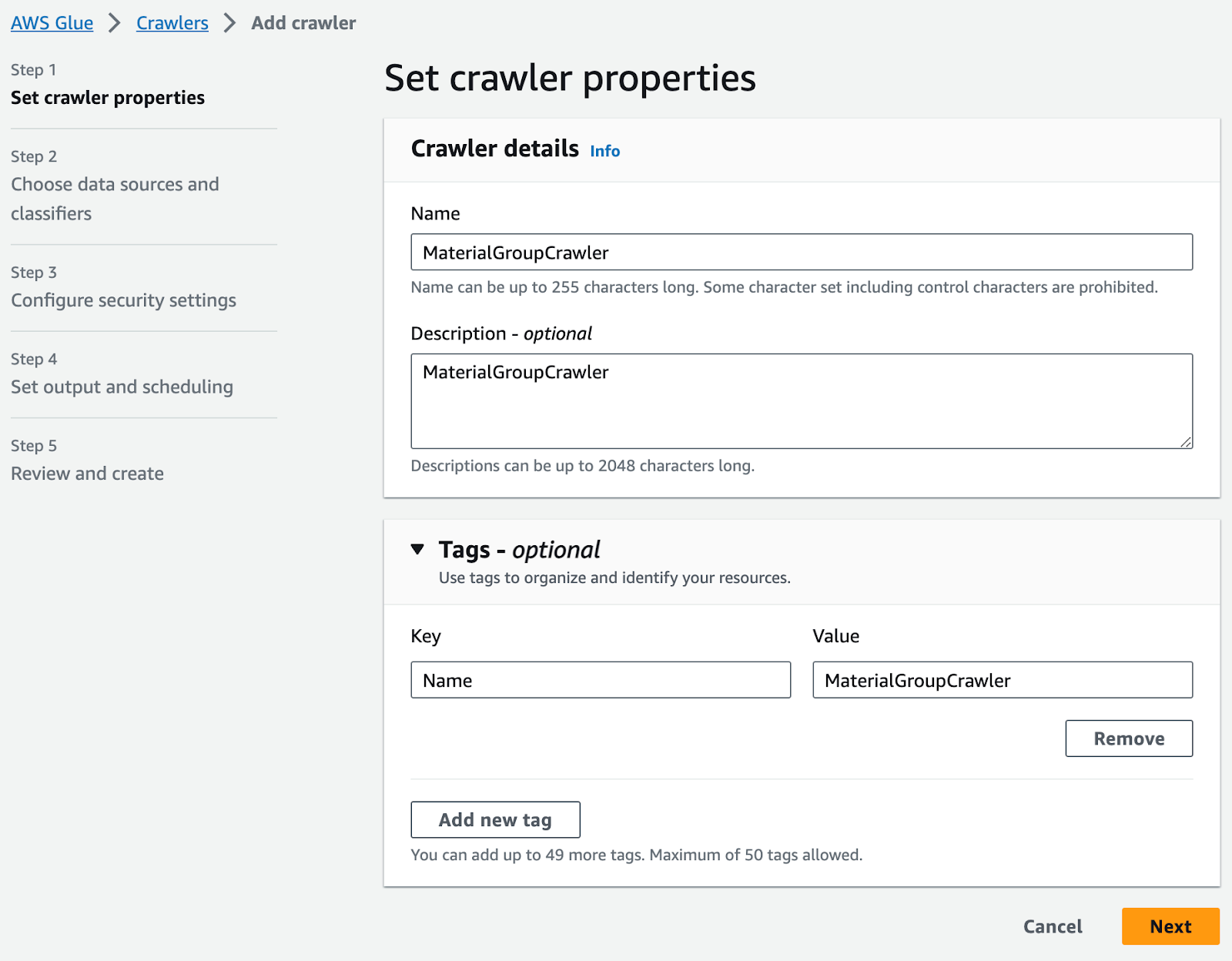
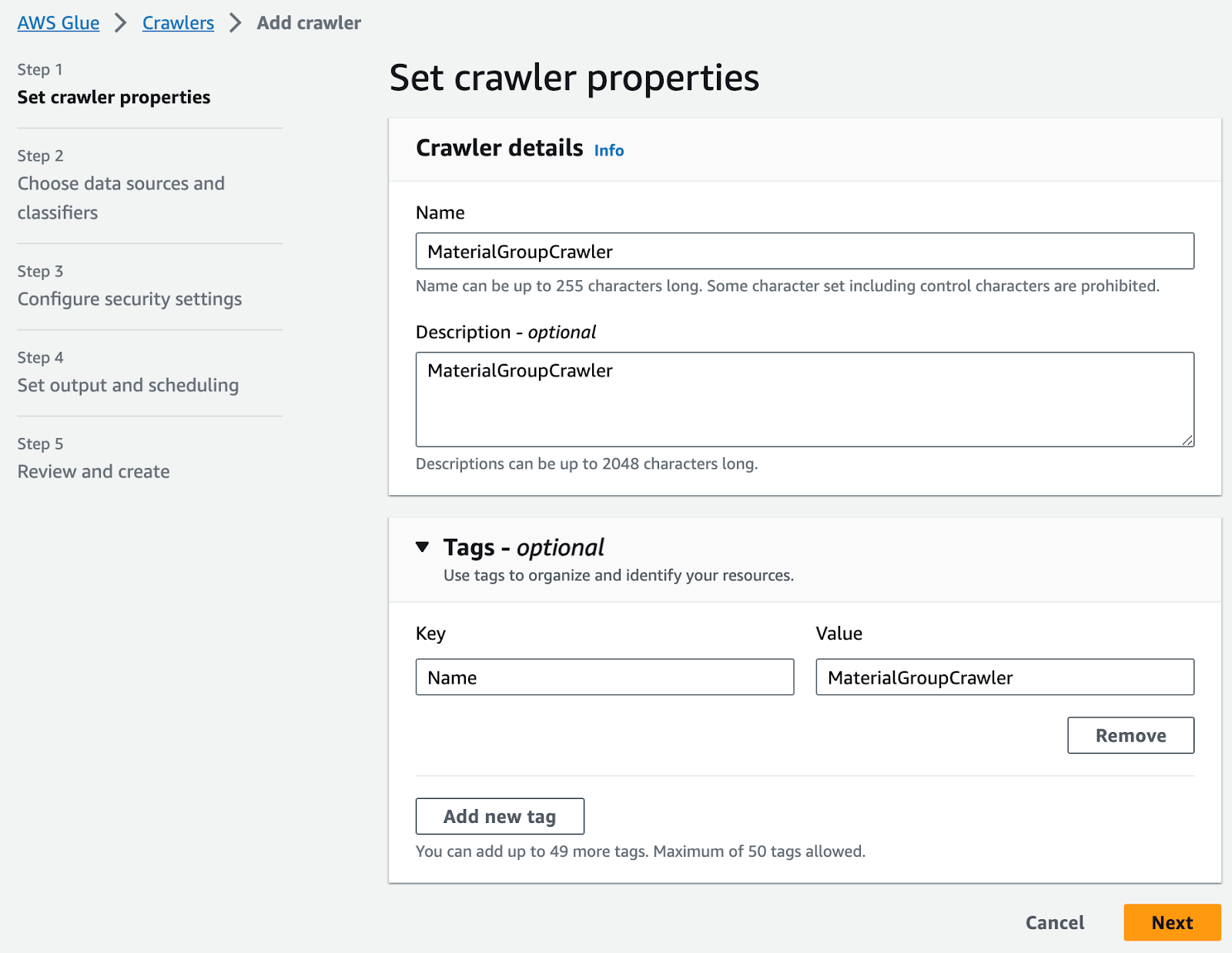
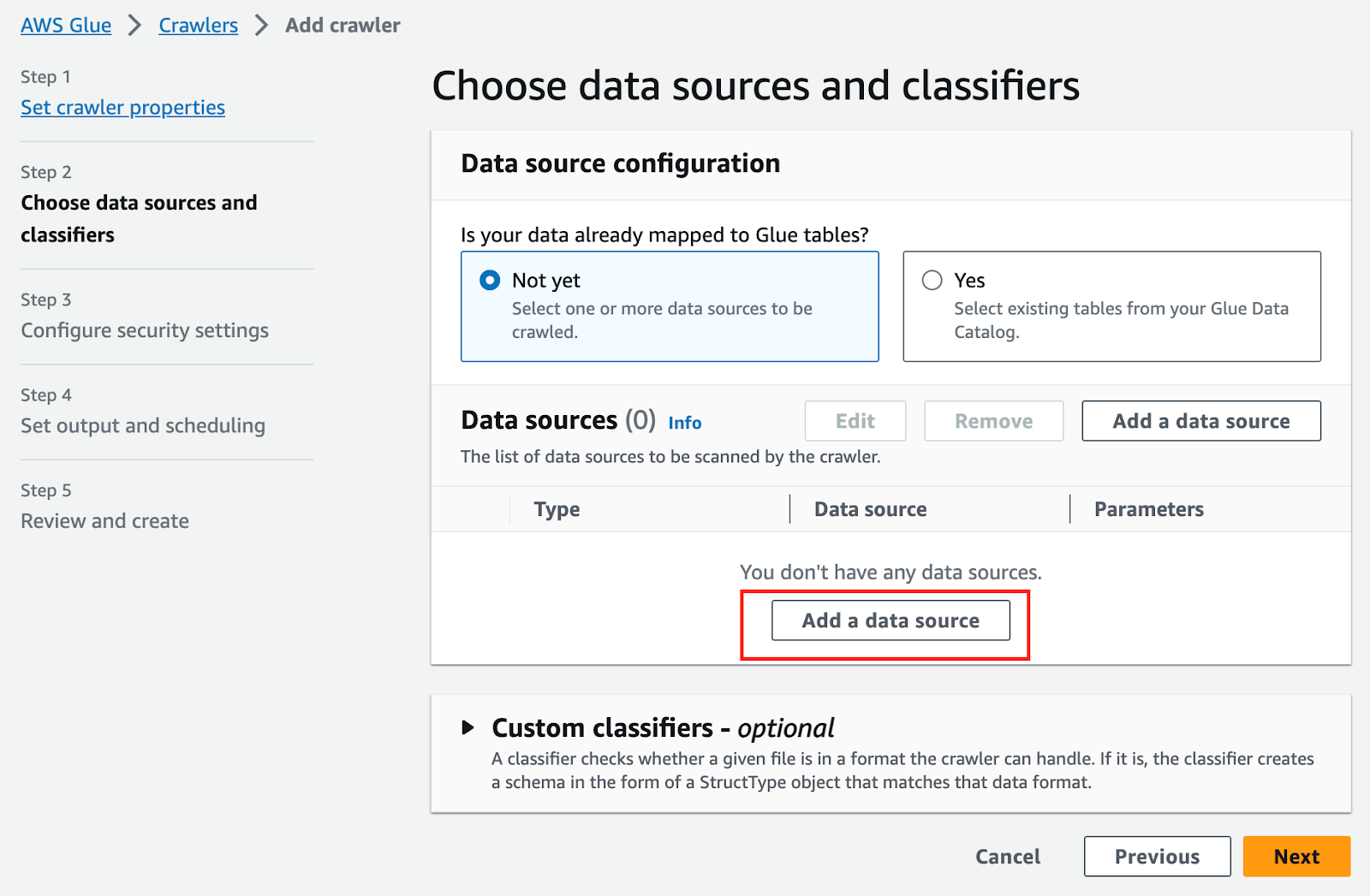
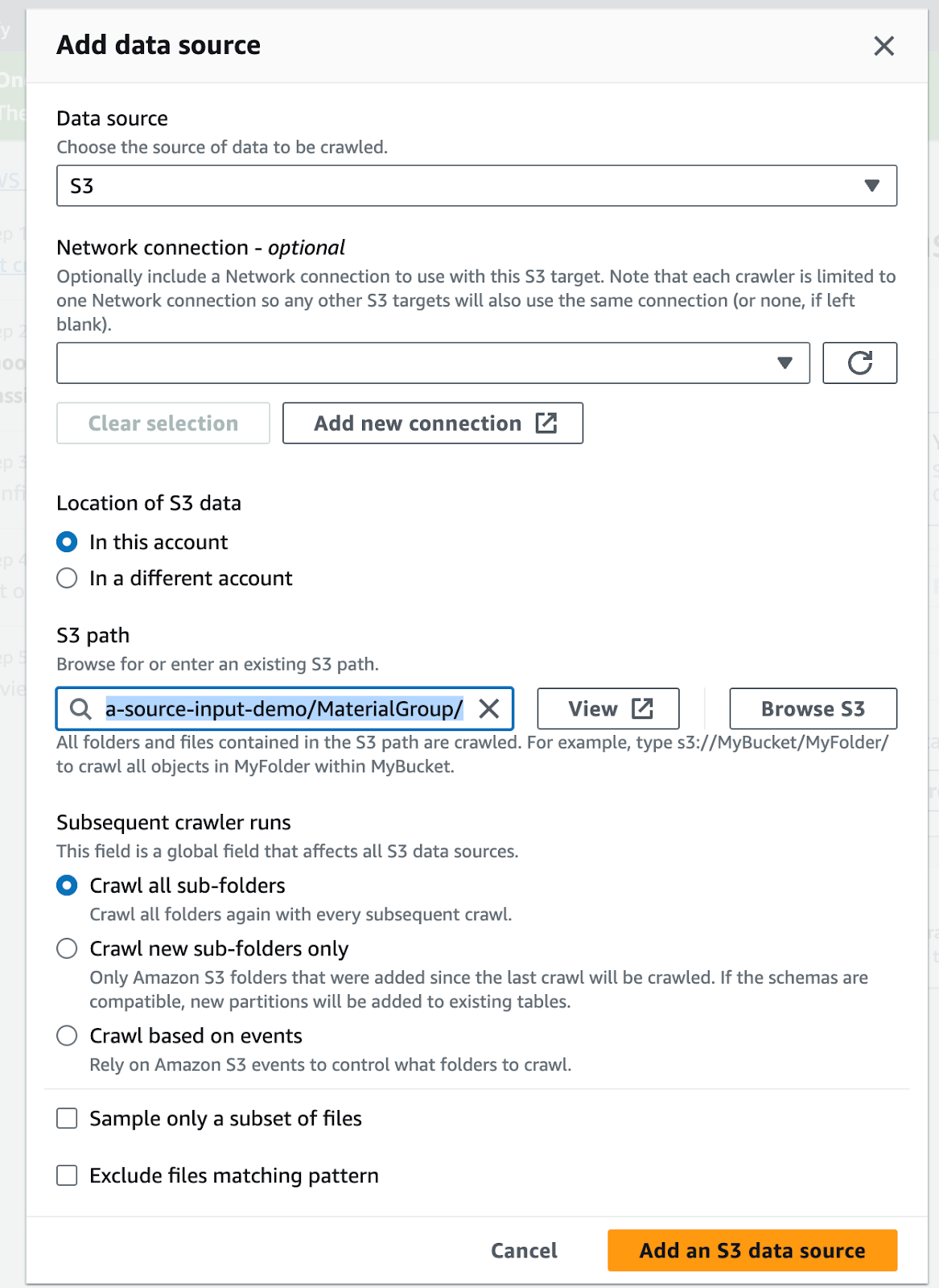
S3データソースを追加
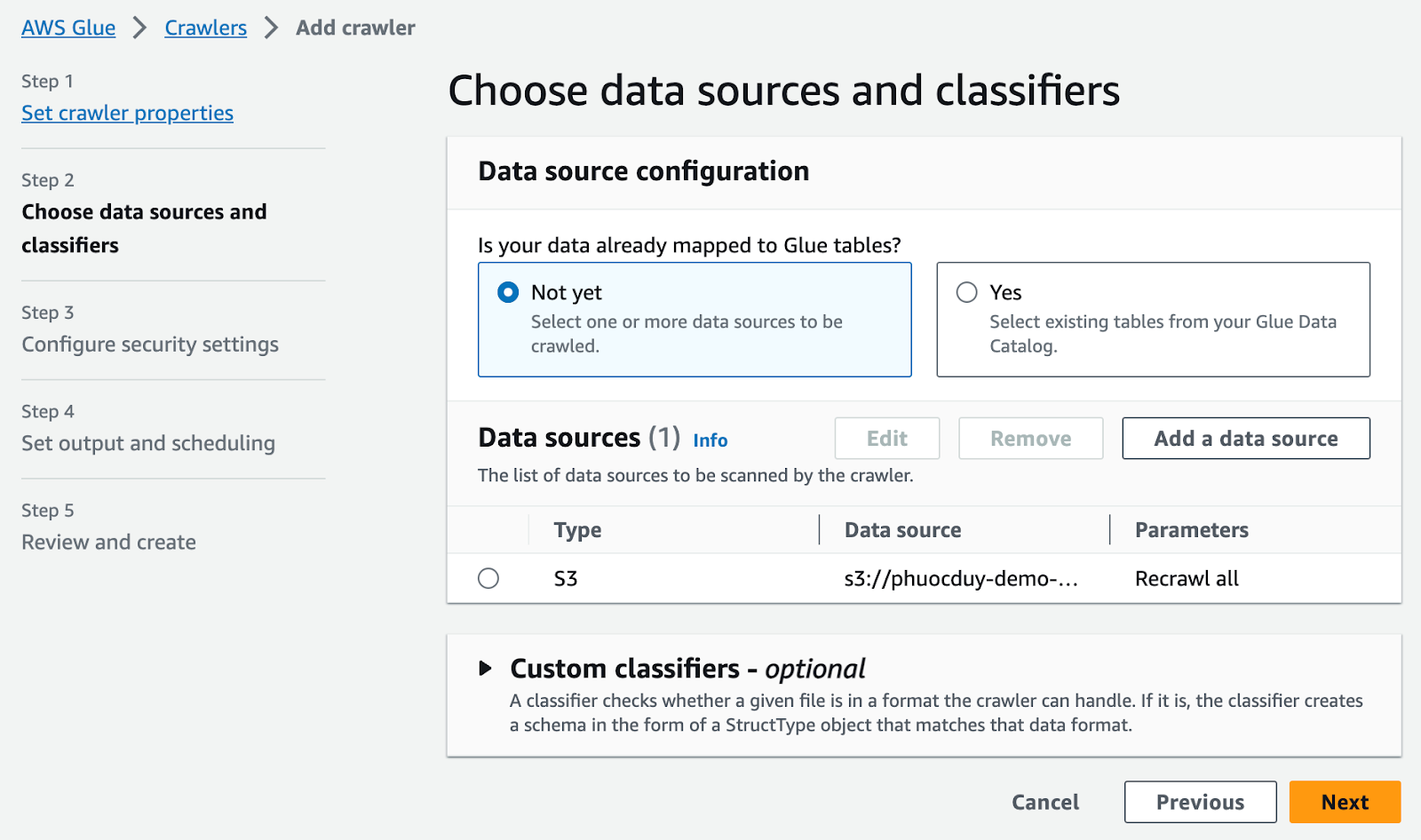
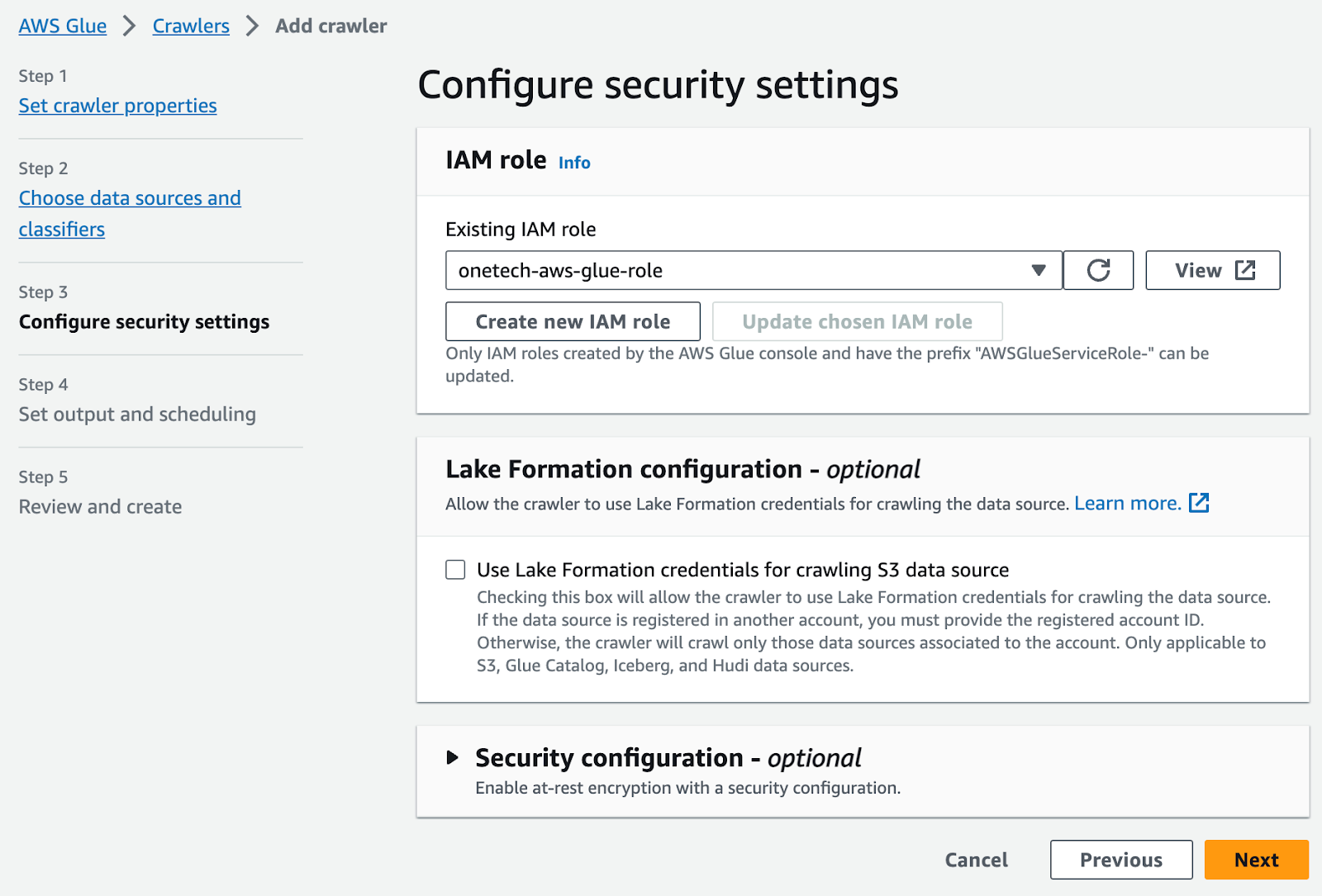
次へ選択
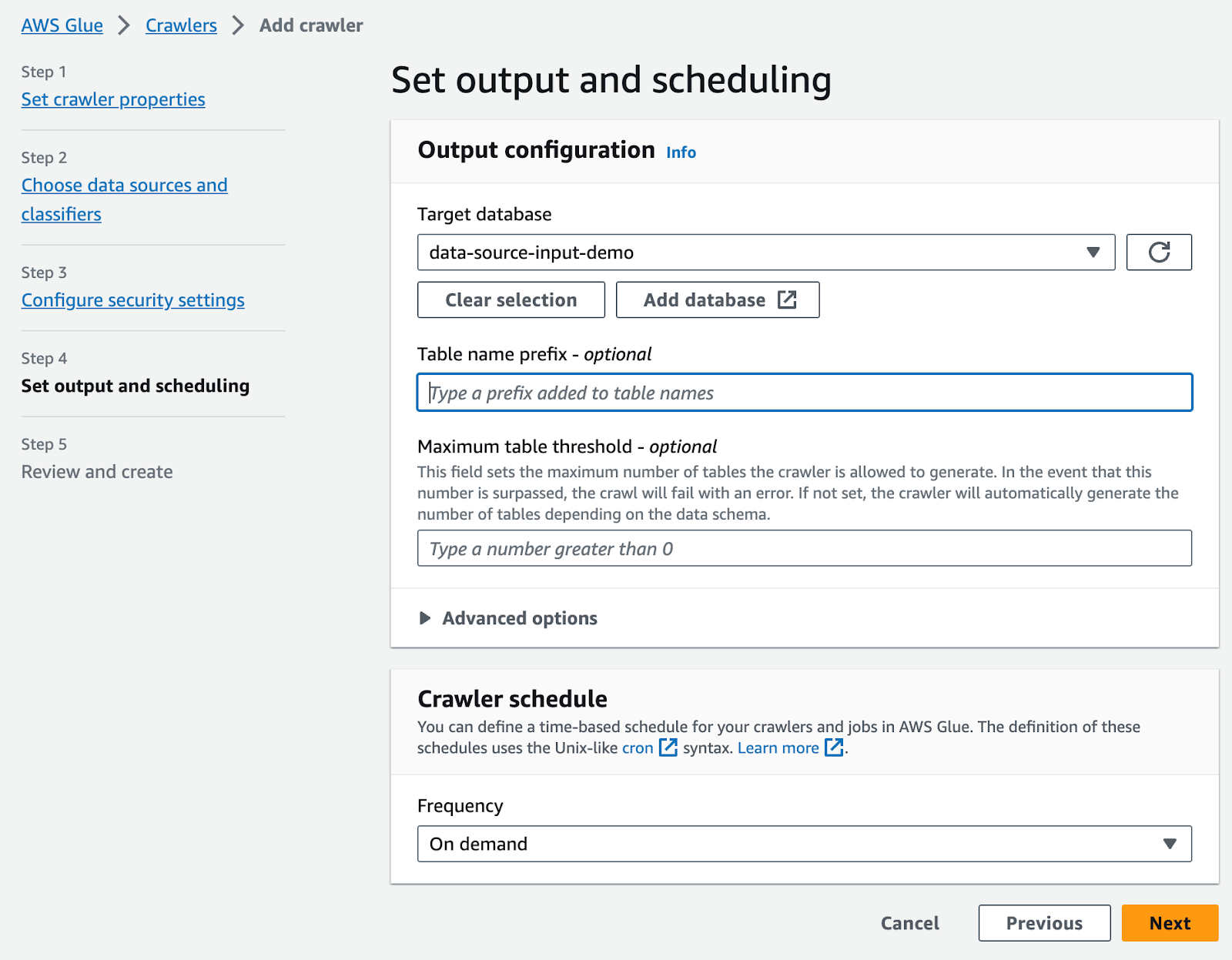
クローラースケジュールをオンデマンドに設定
次へを選択
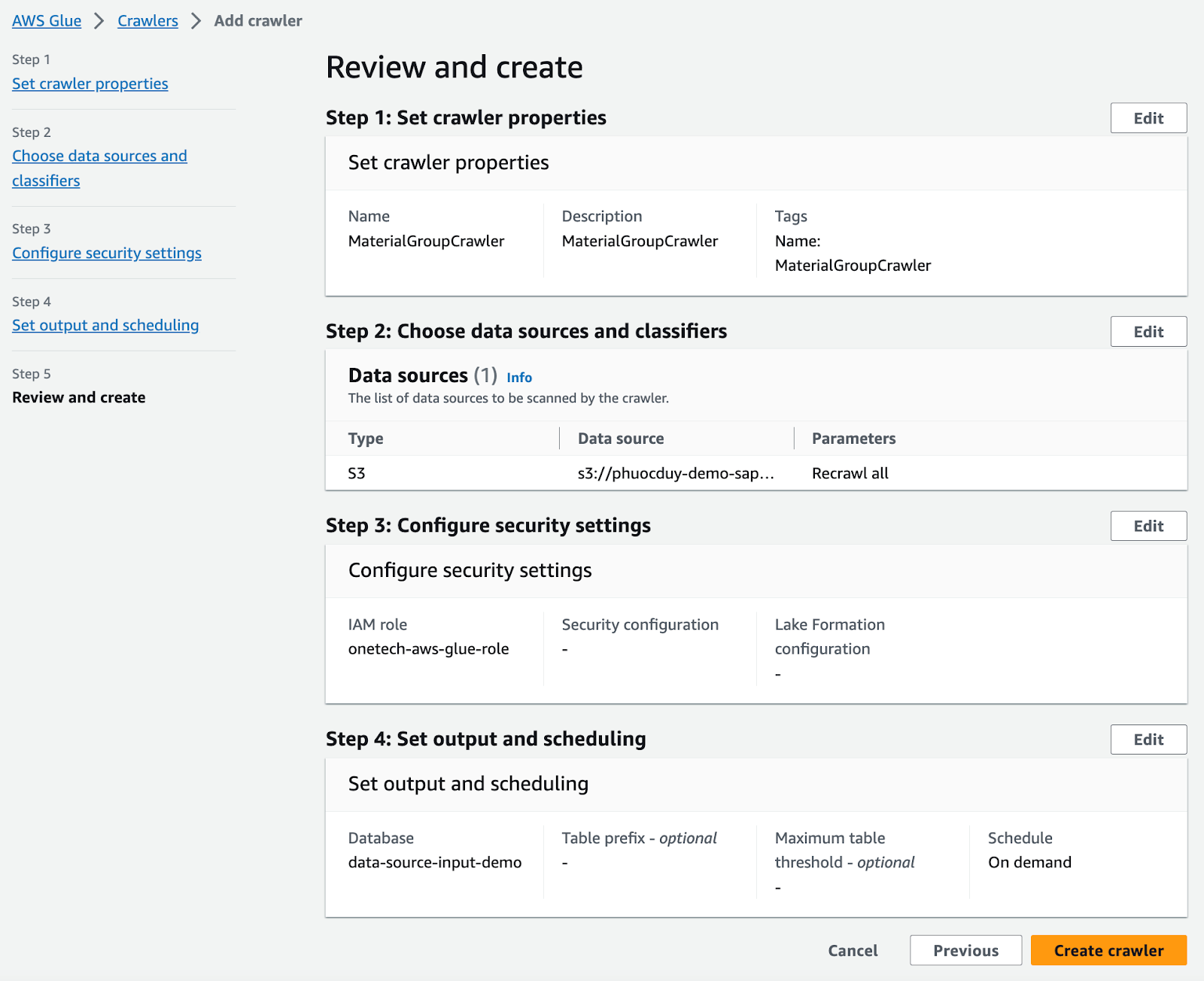
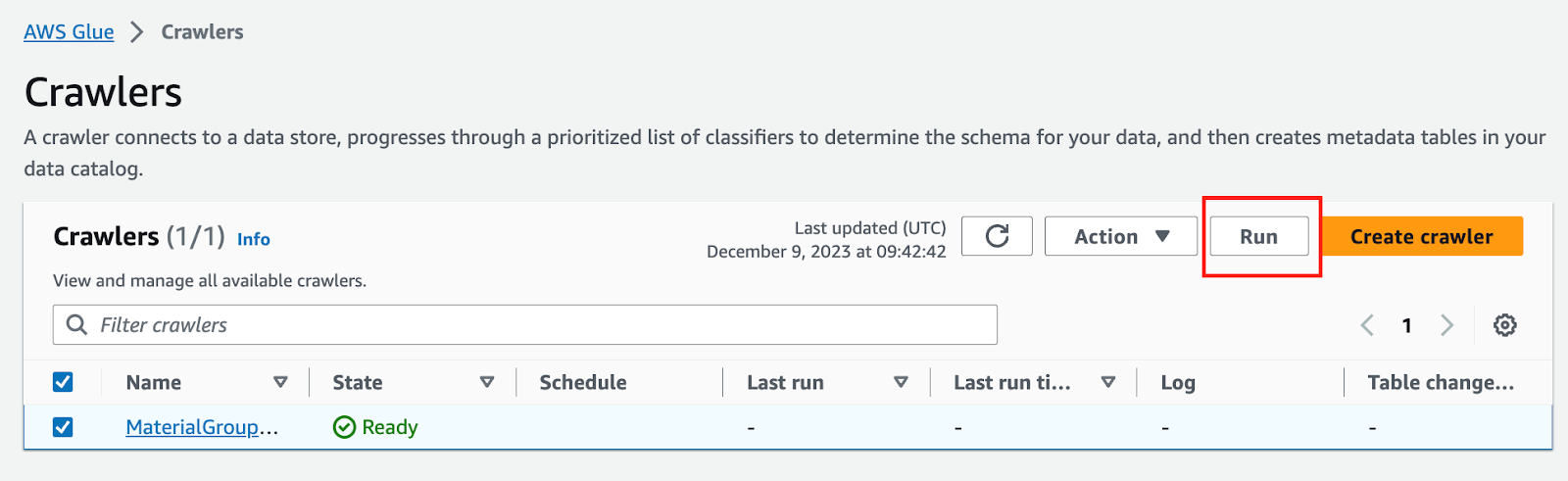
成功したら、以下のようなテーブルが作成されます:
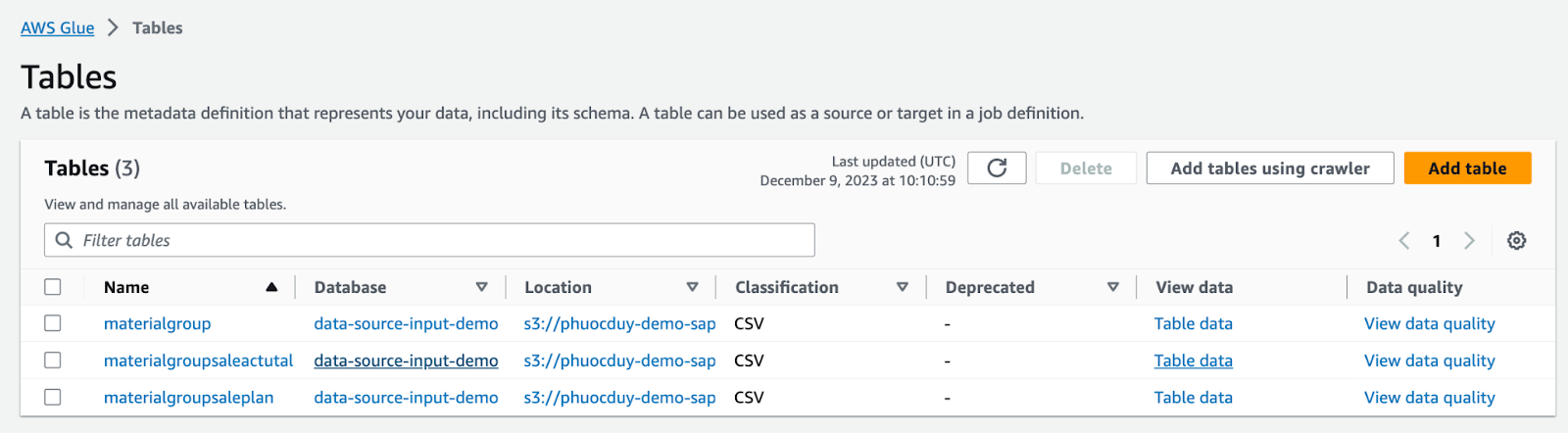
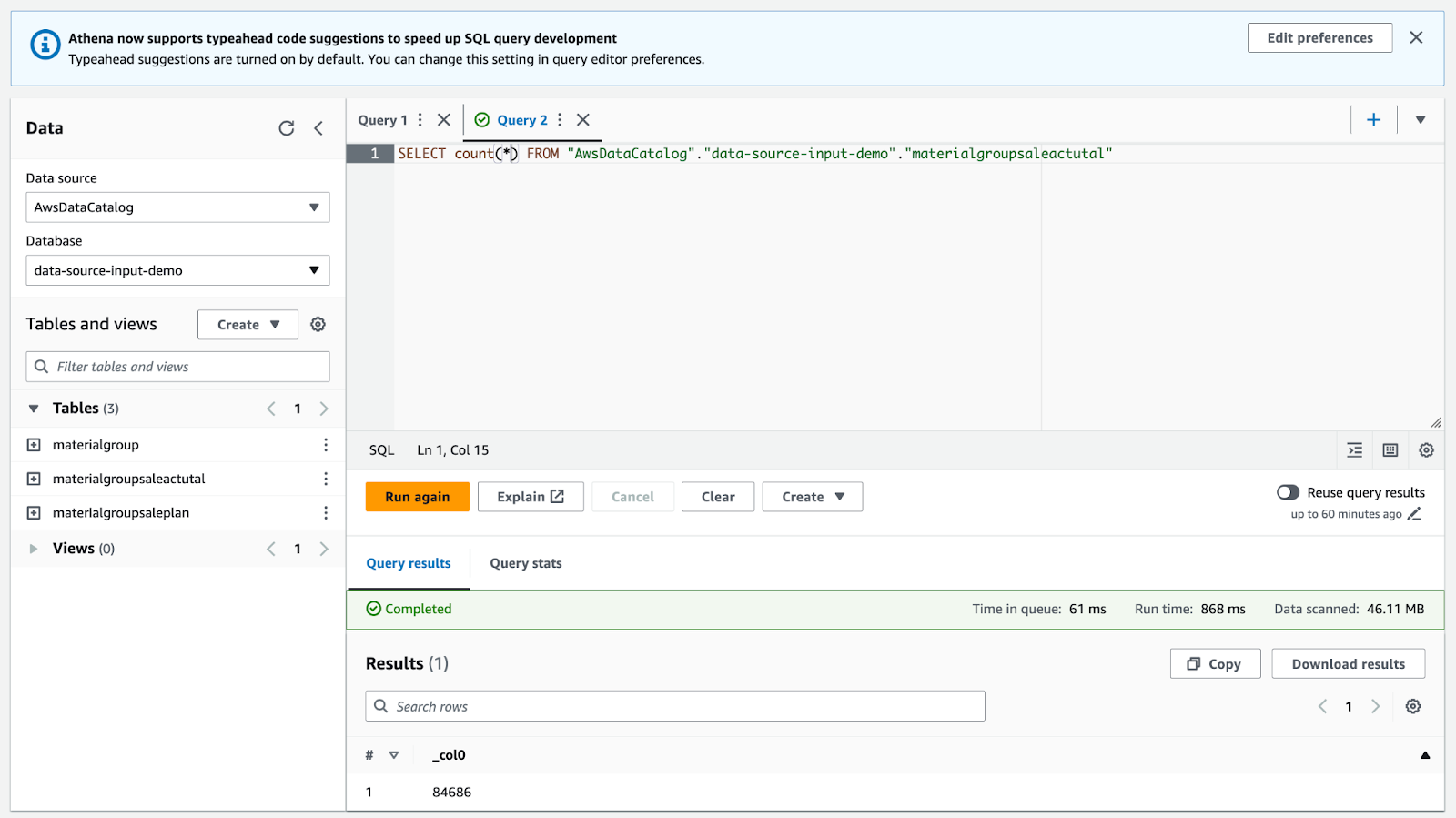
6. データカタログからParquetファイルへのデータ変換用のJobを作成する
Parquetはデータストレージの一般的なフォーマットであり、特にビッグデータ分析の領域でよく使われます。
Parquetの特徴:
- CSVやJSONのような行ではなく列ごとにデータを格納するため、ランダムアクセスが効率的です。
- 高い圧縮率のアルゴリズムを使用し、通常のテキスト形式のファイルよりもサイズを1/3に減らします。
- 並行読み書きに最適化されており、分散システム上でのビッグデータ処理に適しています。
- Hadoopエコシステム(HDFS、Hive、Spark)との互換性が高いです。
- Python、R、Javaなどの一般的なプログラミング言語にはParquetの読み書きをサポートするライブラリがあります。
これらの利点から、Parquetは徐々にCSVやJSONなどの古いフォーマットを置き換える傾向にあります。
ジョブを作成する手順:
AWS Glueのコンソールにアクセス > ETL Jobs > Visual ETL > AWS Glue Studio
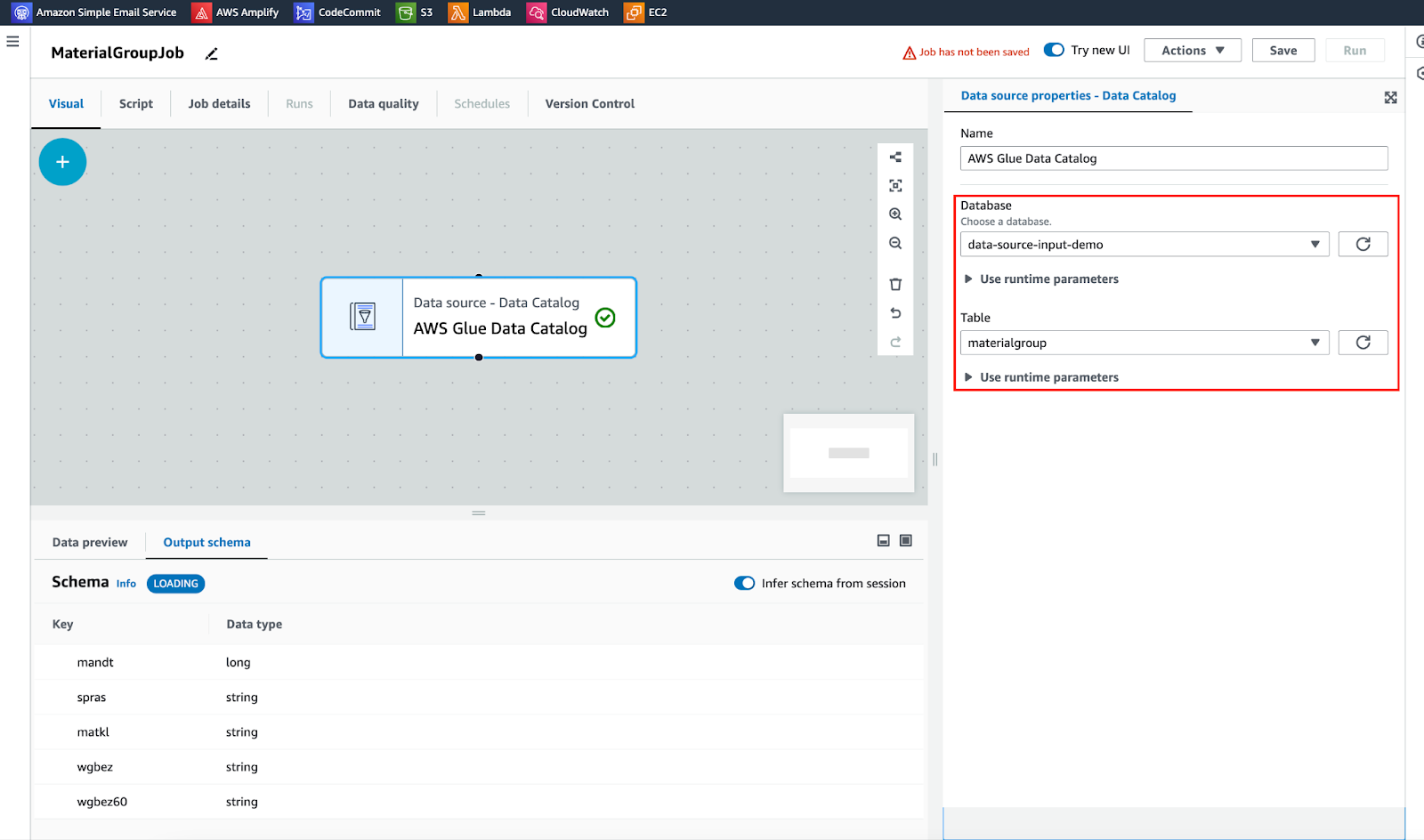
出典: Aws Glue データカタログ
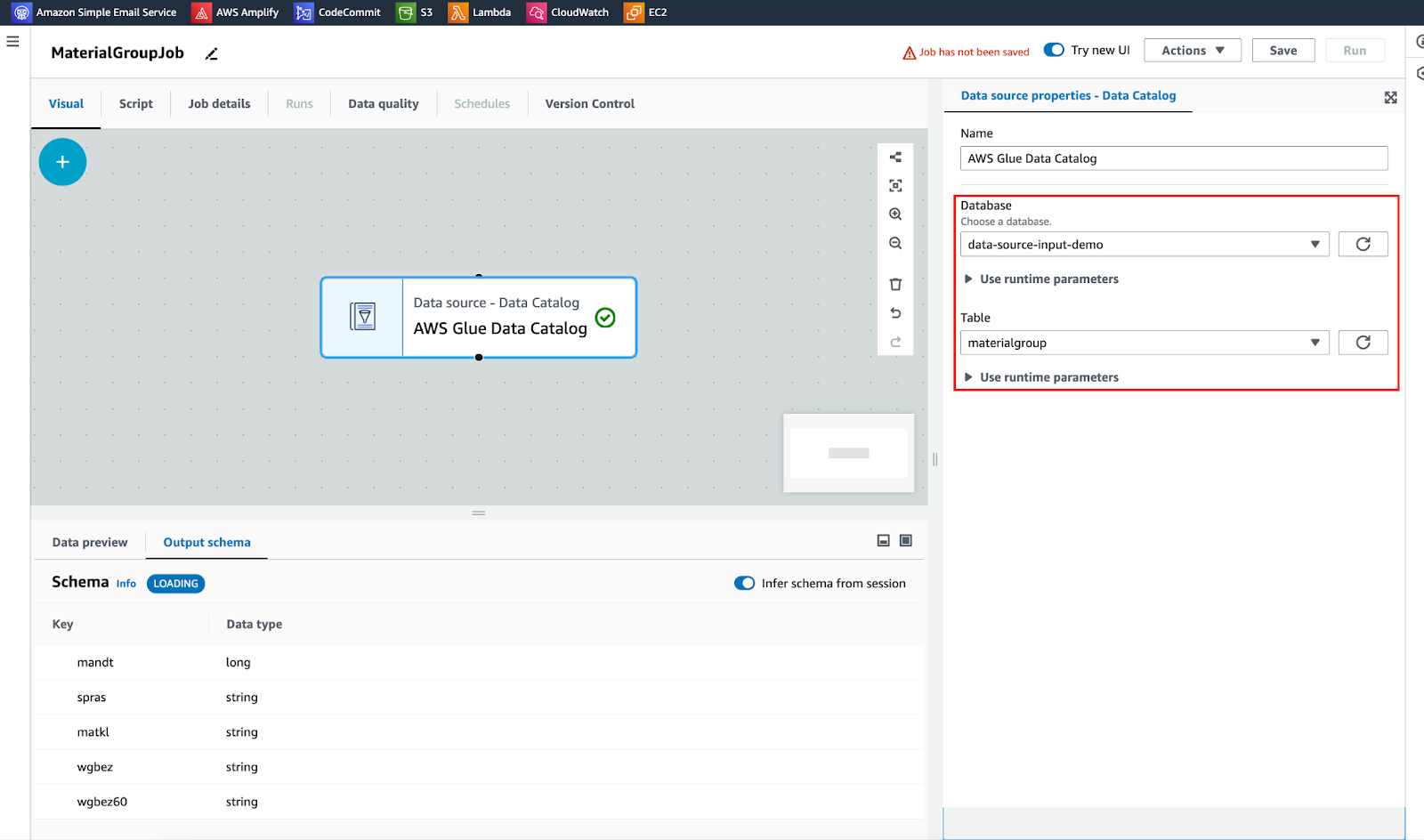
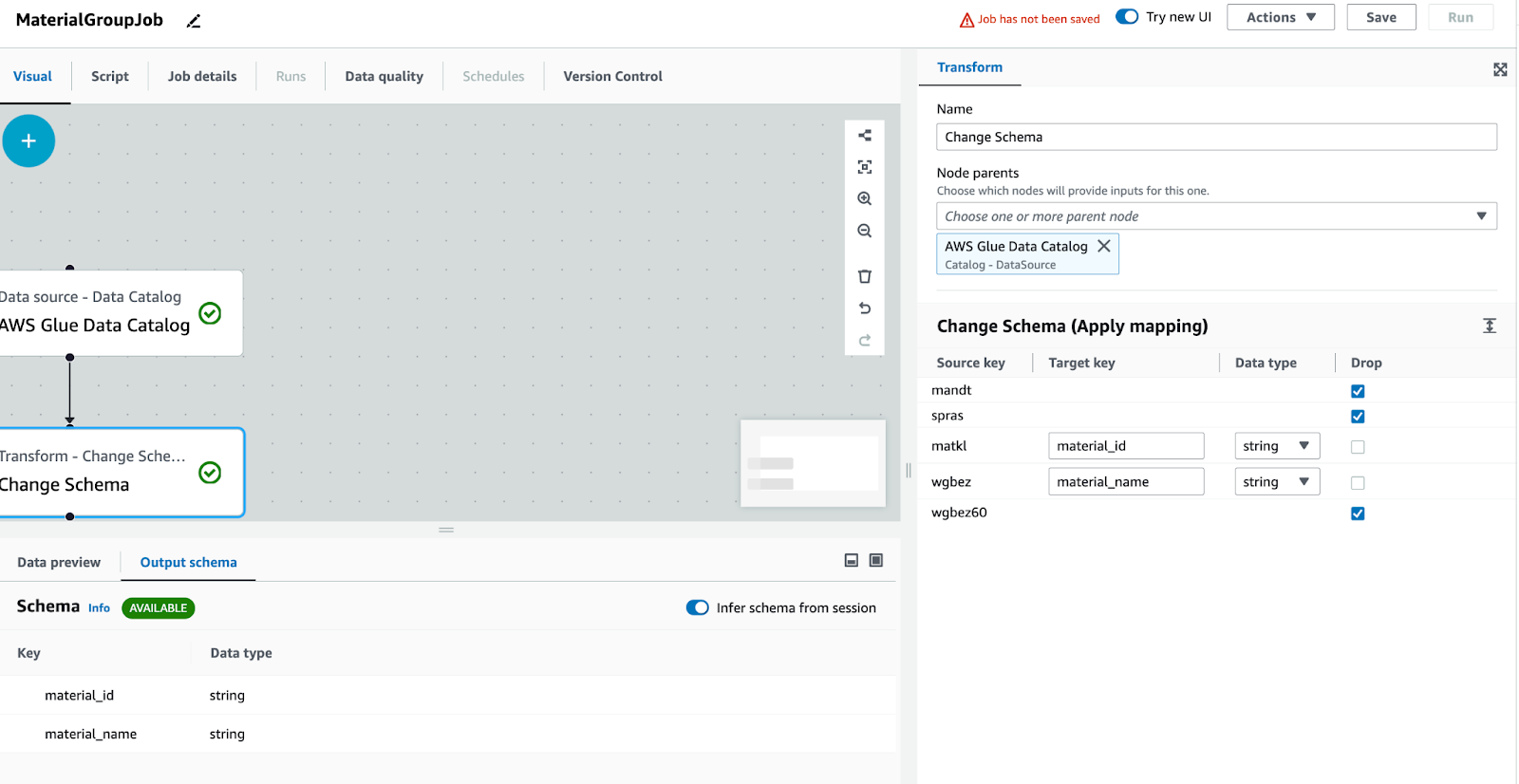
変換: スキーマを変更します。目的は列名を修正し、不要な列をエクスポートしないことです。
AWS Glue スタジオ
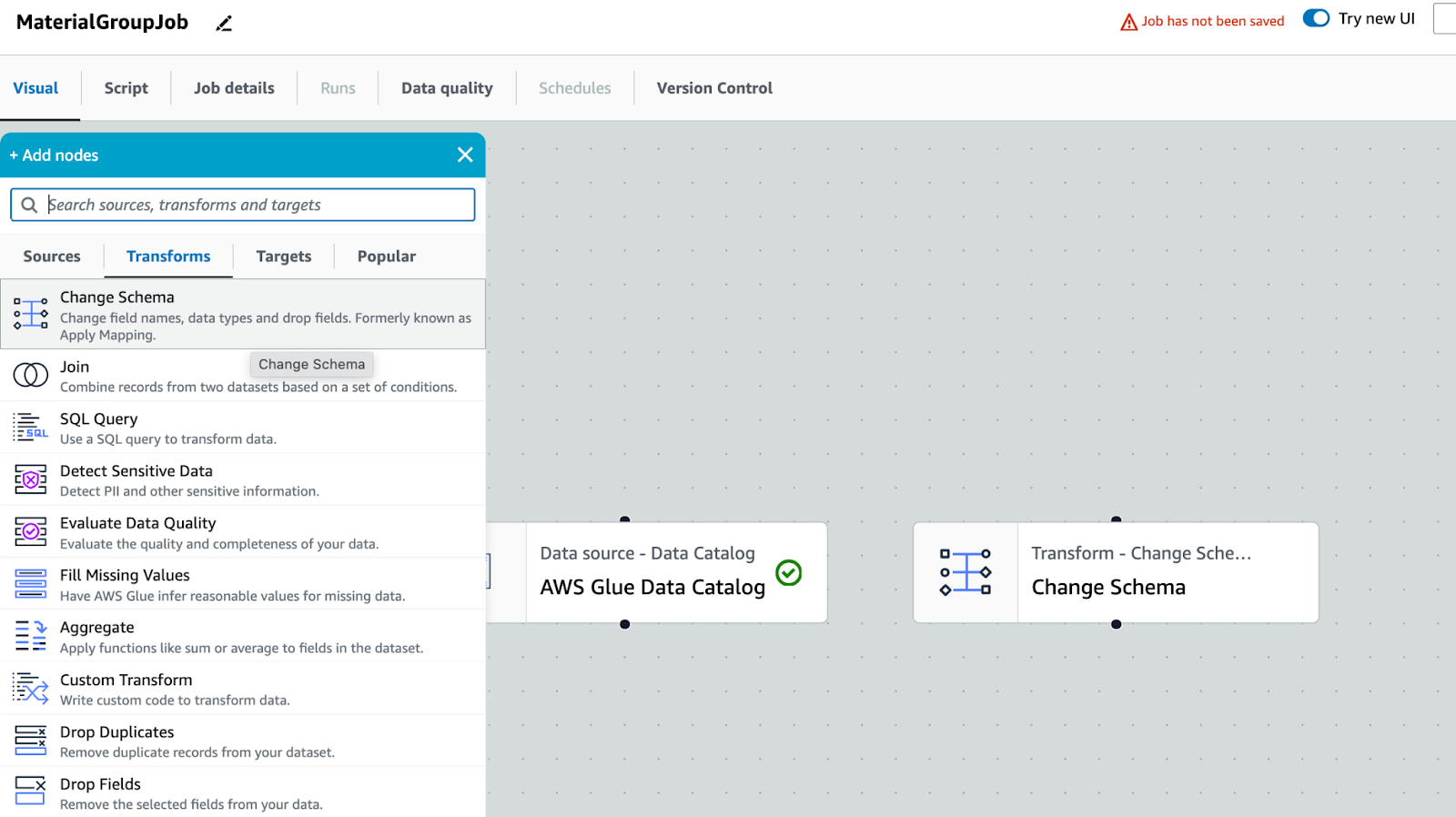
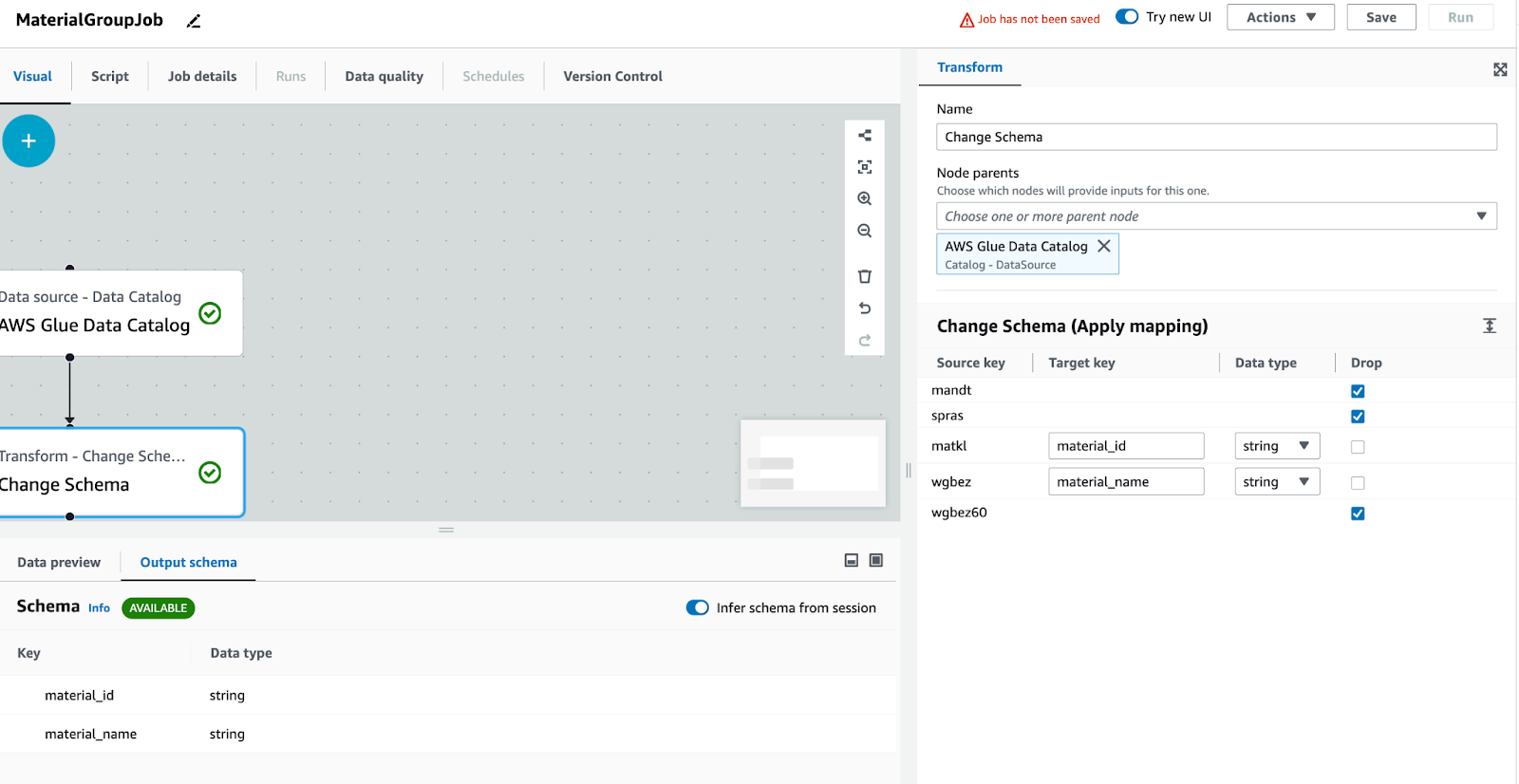
他の列が使用されていない場合は削除します
ターゲット: Amazon S3、ジョブデータが処理された後、寄木細工ファイルは S3/data-source-output-demo/ に保存されます。
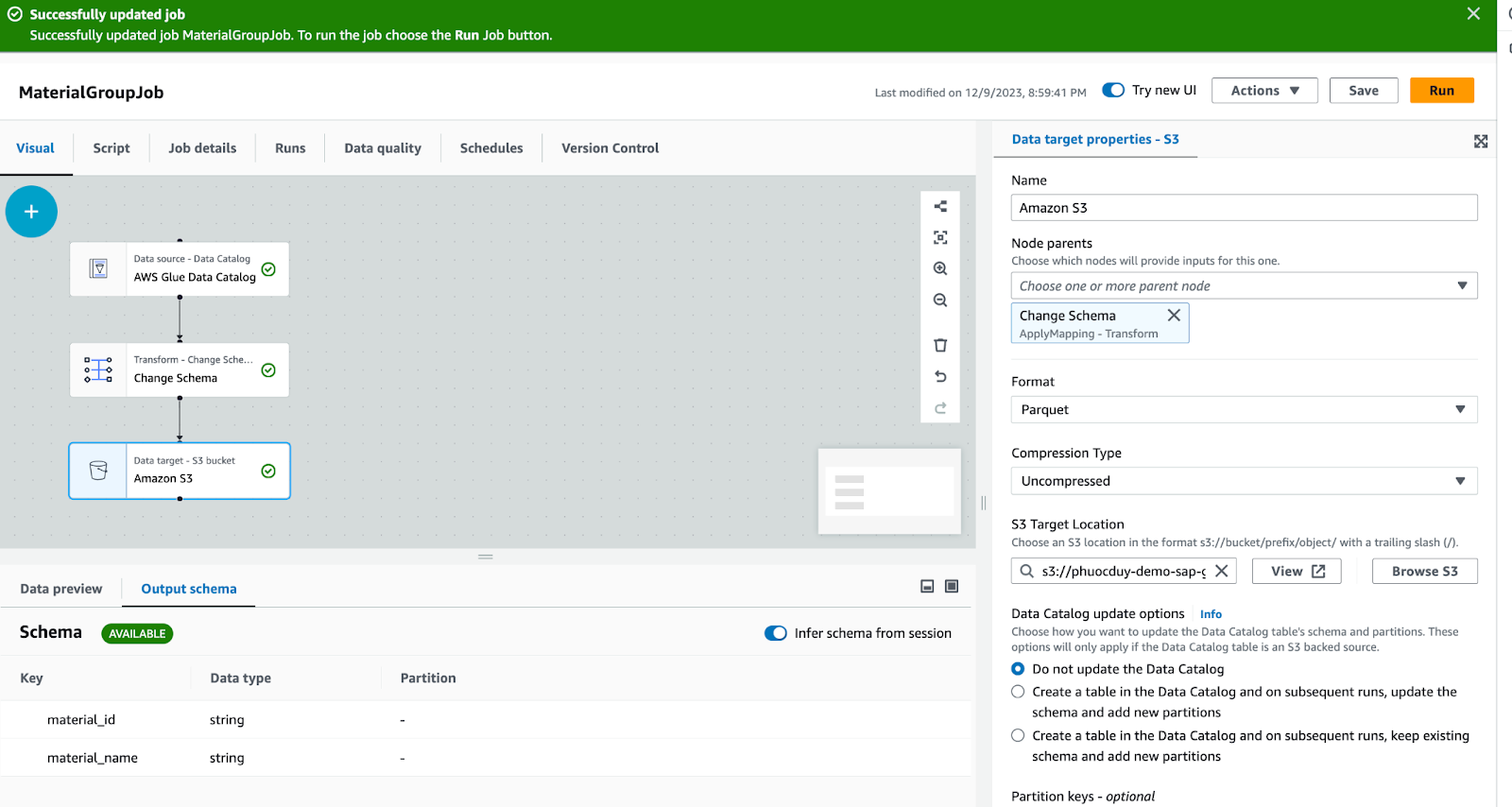
「実行」ボタンをクリックして、ジョブでデータを処理させます。

ジョブの実行が終了したら、S3/data-source-output-demo/ に移動して確認します。
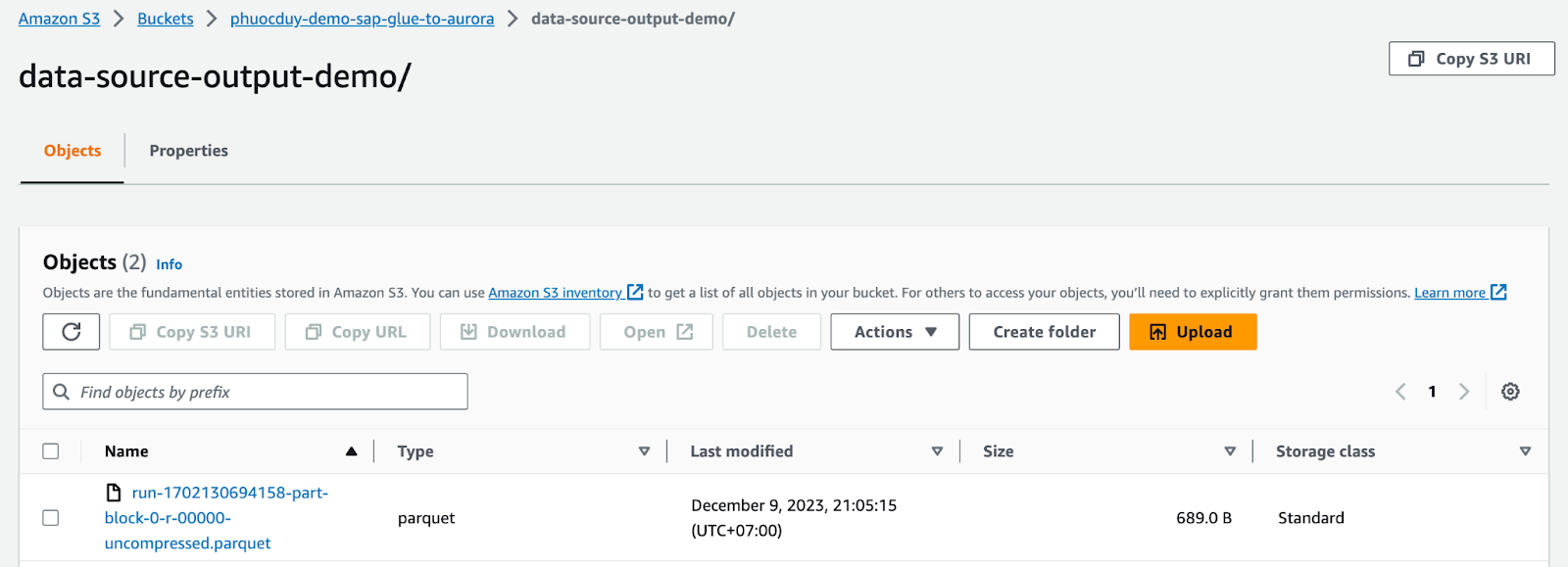
寄木細工のファイルに問題がないことを確認したら、Aurora Mysql へのデータのインポートに進みます。
7. もう一度ステップ 6 を利用して、上記のデータファイルを Aurora に取り込みます
mysql にインポートするには、まず Aurora mysql データベースを作成する必要があります.
Link hướng dẫn Aurora の作成手順へのリンク。
この例では、Aurora は mysql 5.7 のパブリック アクセスを使用します。
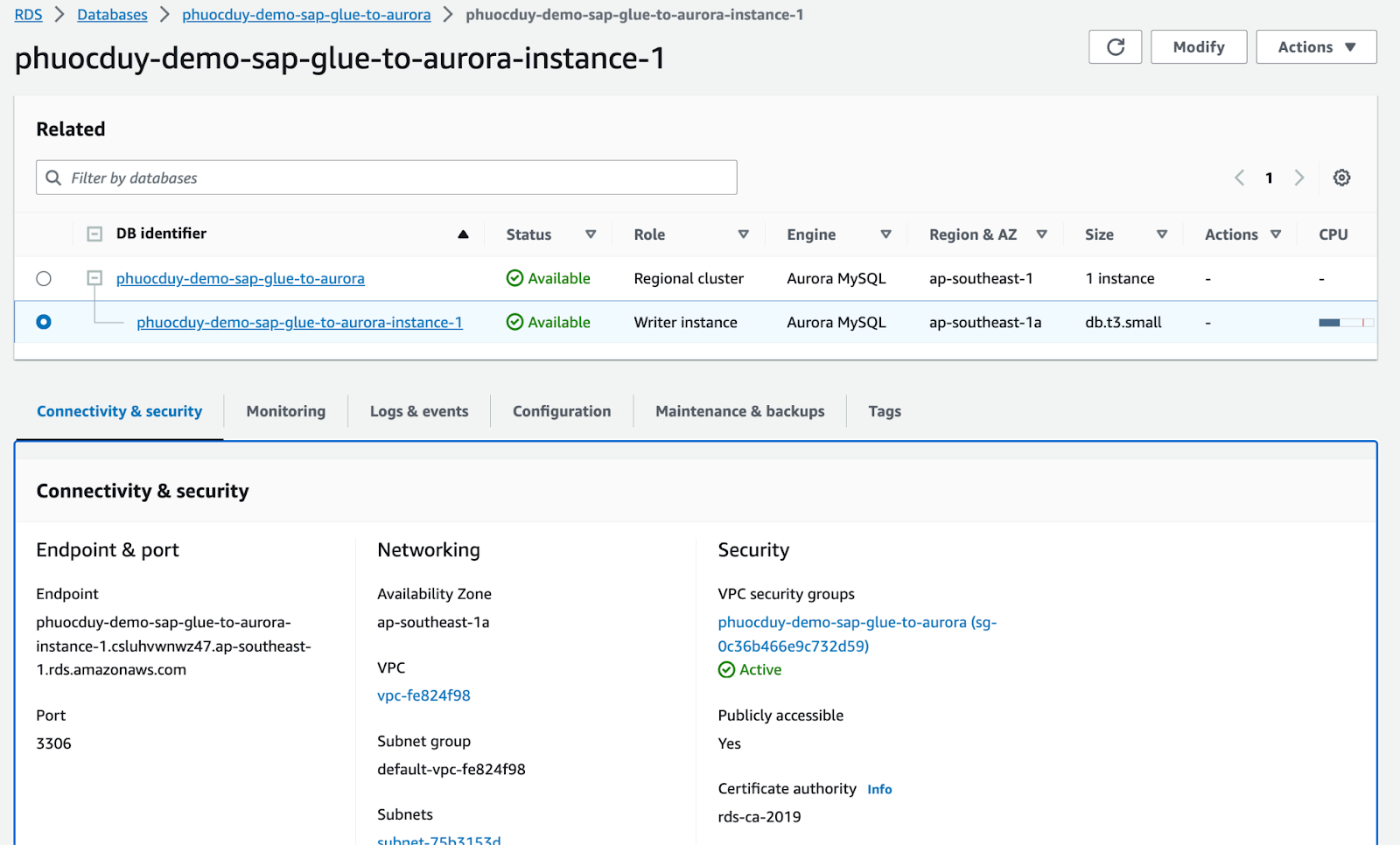
Aurora へのインポートを実行する
出典: Aws Glue データカタログ
変換: スキーマを変更します。目的は列名を修正し、不要な列をエクスポートしないことです
他の列が使用されていない場合は削除します
このステップで引き続きターゲット データを Aurora に取り込むには、Visual を使用することはできませんが、スクリプトからコードに切り替える必要があります。 以下のコードを参照できます
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node1702178138796 = glueContext.create_dynamic_frame.from_catalog(
database="data-source-input-demo",
table_name="materialgroup",
transformation_ctx="AWSGlueDataCatalog_node1702178138796",
)
# Script generated for node Change Schema
ChangeSchema_node1702178150269 = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node1702178138796,
mappings=[
("matkl", "string", "material_id", "string"),
("wgbez", "string", "material_name", "string"),
],
transformation_ctx="ChangeSchema_node1702178150269",
)
AmazonS3_node1702130225660 = glueContext.write_dynamic_frame.from_options(
frame=ChangeSchema_node1702178150269,
connection_type="mysql",
connection_options={
"url": "jdbc:mysql://aurora-endpoint-url:3306/database_name",
"dbtable": "table_name",
"user": "admin",
"password": "password"
},
transformation_ctx="AmazonS3_node1702130225660",
)
job.commit()結果
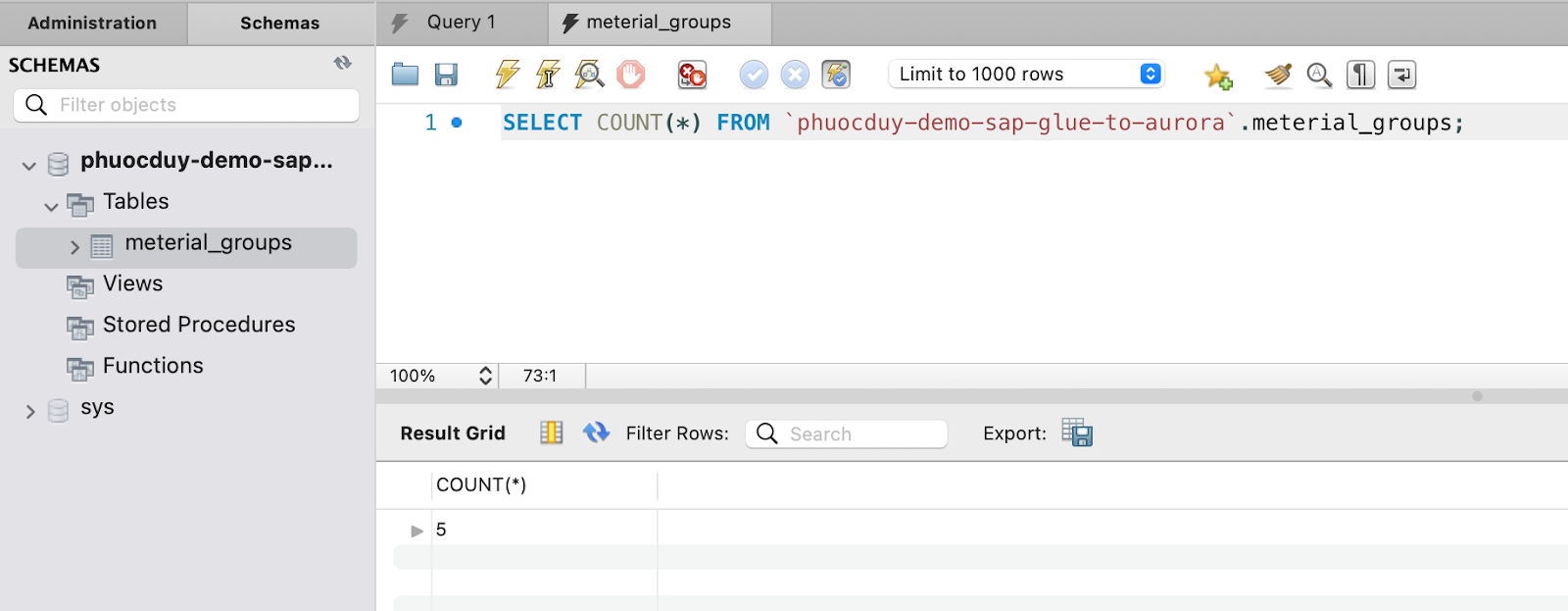
その後、実行をクリックして結果を監視します:

結果を確認してください:
がんばってください!
関連するすべてのリソースを削除して、余分な費用が発生しないようにしてください。